Introduction
The goal of the Data Science Infrastructure Project (DSI) is to manage data through metadata capture and curation. DSI capabilities can be used to develop workflows to support management of simulation data, AI/ML approaches, ensemble data, and other sources of data typically found in scientific computing.
- DSI is designed to be flexible and with these considerations in mind:
Data management is subject to strict, POSIX-enforced, file security.
DSI capabilities support a wide range of common metadata queries.
DSI interfaces with multiple database technologies and archival storage options.
Query-driven data movement is supported and is transparent to the user.
The DSI API can be used to develop user-specific workflows.
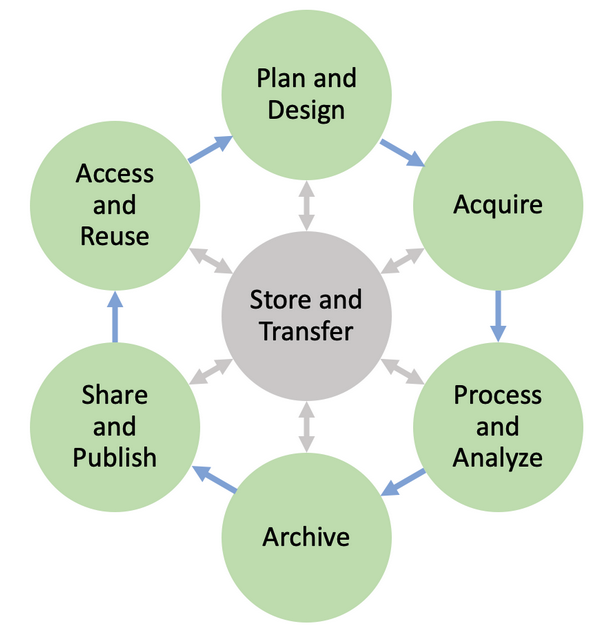
A depiction of data life cycle can be seen here. The DSI API supports the user to manage the life cycle aspects of their data.
DSI system design has been driven by specific use cases, both AI/ML and more generic usage. These use cases can often be generalized to user stories and needs that can be addressed by specific features, e.g., flexible, human-readable query capabilities.
Implementation Overview
The DSI API is broken into three main categories:
Readers/Writers: frontend capabilities that DSI users will use to import/export data.
Backends: objects that are used to interact with storage devices and other ways of moving data.
DSI Core: the middleware that contains the basic functionality to use the DSI API. This connects Readers/Writers to Backends through several modules exposed to users.
Expected Data Standards
Before using DSI, users should first standardize their data in a format that can be represented as a table. DSI supports many widely used formats, including, but not limited to, CSV, JSON, YAML, TOML, and in-memory dictionaries. If the data is structured in a unique format, users can create an external DSI reader by following the steps in Custom DSI Reader.
When using a DSI-supported Reader, each data point is expected to be a discrete value — not a nested structure. Users must flatten any nested data to ensure compatibility with DSI.
Metadata is important for many data workflows and should be stored with the data when relevant. For example, if simulation parameters are required for future analysis, that metadata should be included in the same table as the data.
Advanced users familiar with database relationships can also load a complex relational schema into DSI alongside their data. This requires prior knowledge of primary and foreign keys, as well as how columns across tables should be related.
Users must load this relational schema as a JSON into DSI using a Schema Reader. For more information on formatting the schema file correctly, refer to Cloverleaf (Complex Schemas).
DSI Readers/Writers
Readers/Writers transform an arbitrary data source into a format that is compatible with the DSI core. The parsed and queryable attributes of the data are called metadata – data about the data. Metadata shares the same security profile as the source data.
Data Readers parse an input file of its metadata and data and stores it within DSI memory. Data Writers convert metadata and data stored in DSI to an output file - ex: an image or a CSV
- Currently, DSI has the following Readers:
CSV
JSON
Schema (A complex schema reader)
YAML1
TOML1
Collection (To load a Python dictionary or OrderedDict)
Bueno
Ensemble (Reader to ingest ensemble data. Ex: the Wildfire ensemble dataset . Assumes each data row is a separate sim.)
DublinCoreDatacard (Data card that adheres to the Dublin Core metadata standard )
SchemaOrgDatacard (Data card that adheres to the Schema.org metadata standard )
GoogleDatacard (Data card that adheres to the Google Data Cards Playbook )
- Currently, DSI has the following Writers:
Csv_Writer
ER_Diagram
Table_Plot
DSI Backends
Backends are an interface between the DSI Core and a storage medium designed to support a user-needed functionality. DSI’s default backend is SQLite, but users can load other ones instead.
Users can interact with a backend by ingesting data into one with DSI, querying its data through abstracted find functions, or processing its data into DSI. Users can also find instances of an object in a backend, display a table’s data, or view statistics of each table in a backend.
Certain backends are read-only so data cannot be ingested or updated, only queried.
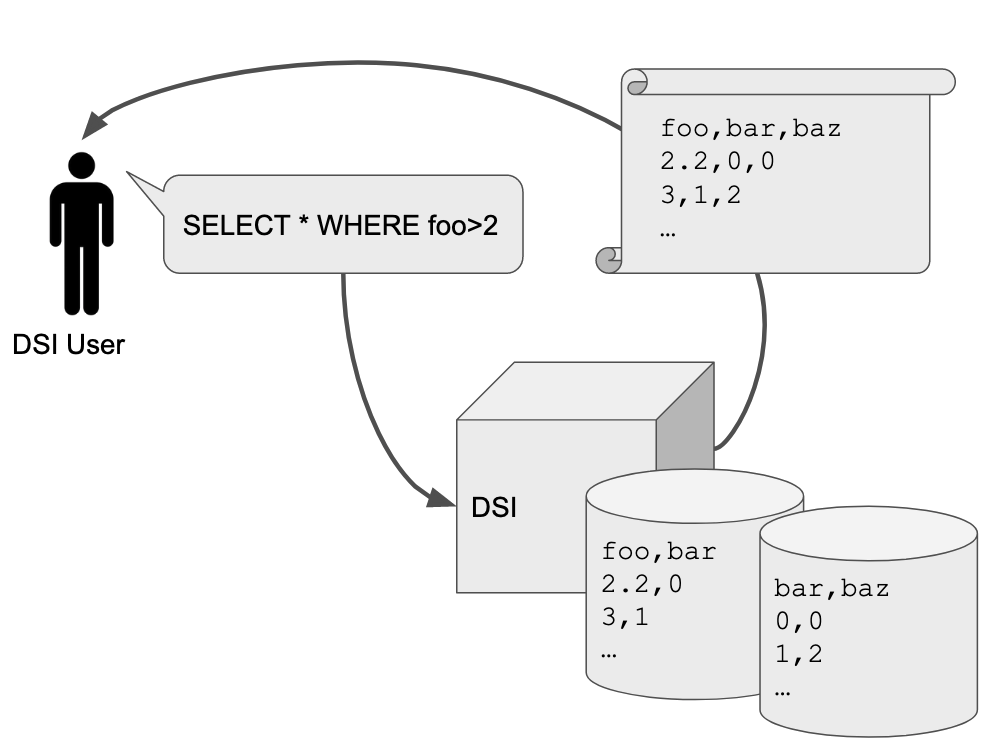
In this example user story, the user has metadata about their data stored in DSI storage of some type. The user needs to extract all instances of the variable foo. DSI backends find data from the DSI metadata to locate and return all such information.
DSI currently has two categories of backends:
- Filesystem Backends - Create a permanent database file in the user’s local directory:
SQLite: Python based SQL database and backend; the default DSI API backend. Supports POSIX-enforced file permissions.
DuckDB: In-process SQL database designed for fast queries on large data files. Supports POSIX-enforced file permissions.
- Webserver Backends - Create a connection to a remote data platform for users to retrieve data in-memory:
NDP (Read-only): Connection to data on the National Data Platform
Oceans11 (Read-only): Connection to data on DSI’s open data server:
OSTI (Read-only): Connection to data hosted by the Department of Energy’s Office of Scientific and Technical Information
DSI Core
DSI basic functionality is contained within the middleware known as the core. Users will leverage Core to employ Readers, Writers, and Backends to interact with their data. The two primary methods to achieve this are with the Python API or the Command Line Interface API
Slides
Contact Us
For general inquiries or help, reach us at dsi-help (at) lanl.gov
Bugs/Feature Requests: DSI GitHub Requests