


Applications are open until January 10 2026
2026 Co-Design Summer School Focus: Advancing scale-bridge simulations in high explosive applications using HARD at Scale
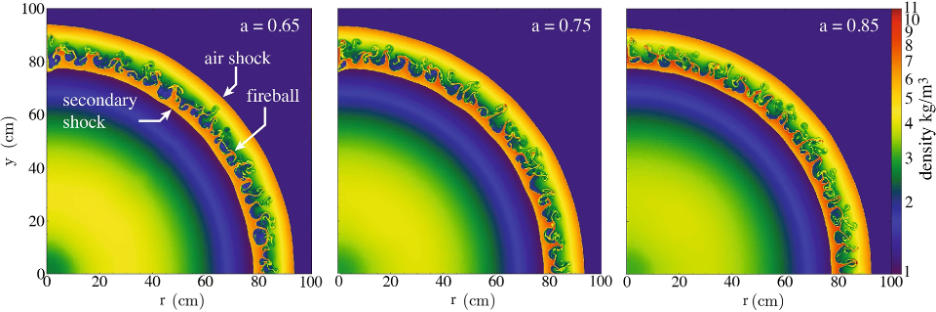 Source: Source: Houim, R. W. (2021). A simplified burn model for simulating explosive effects and afterburning. Shock Waves, 31, 851–875.
Source: Source: Houim, R. W. (2021). A simplified burn model for simulating explosive effects and afterburning. Shock Waves, 31, 851–875.
Many natural and engineered systems, from astrophysical supernovae to nuclear detonations and high-explosive experiments, involve rapid, intense energy release that strongly couples to both hydrodynamic and radiative processes. To understand these phenomena correctly, the study of high-explosive (HE) models is essential. Furthermore, real-world applications span an extraordinary range of spatial and temporal scales, from the submicron chemistry of reaction zones, to the mesoscale dynamics of heterogeneous media, to the macroscale propagation of shock and detonation waves. Many existing works lack the machinery to bridge these scales in a consistent manner. In this work, we propose to incorporate HE physics and multimaterial interface capabilities into HARD, a radiation hydrodynamics code based on the FleCSI framework, to overcome these challenges.
The new framework will accommodate multiple HE-burn models, including programmed burn and reactive burn, by employing an explicit multimaterial formulation. Material interfaces will be captured with a level-set method, while a ghost-fluid approach will enforce the correct pressure and velocity conditions across discontinuities. Leveraging the Singularity-EOS library, each constituent (explosive, product gases, air, etc.) can be described by its own equation of state, preserving numerical stability even in the presence of strong shocks. In parallel, we will augment HARD’s existing hydrodynamic solvers with the additional physics modules required for these capabilities.
Validation will be performed on canonical test problems such as shock-tube and Sedov-blast configurations, as well as on experimentally anchored benchmarks including one-dimensional detonation-tube and two-dimensional cylinder-expansion tests. The ExactPack library will be used to compare simulation results against analytical solutions, providing a thorough quantitative assessment of accuracy and robustness.
The increasing complexity of supercomputers, in both number of nodes and on-node hybridization, forces us to rethink our approach to high-performance computing (HPC). Task-based parallelism provides a promising path forward. CDSS 2026 proposes to use the FleCSI framework, with HARD, as the basis for the simulations. FleCSI is a compile-time configurable framework from LANL. It supports the development of multiphysics applications and introduces a functional programming model that can use multiple backends such as Legion, MPI, and HPX. FleCSI provides different topologies that are then extended via specialization, allowing it to target specific problems. CDSS 2026 aims to run simulations at scale on LANL’s world-class supercomputers.
LA-UR-25-29849