Backends
Backends connect users to DSI Core middleware and allow DSI middleware data structures to read and write to persistent external storage.
Backends are modular to support user contribution, and users are encouraged to offer custom backend abstract classes and backend implementations. A contributed backend abstract class may extend another backend to inherit the properties of the parent.
In order to be compatible with DSI core middleware, backends need to interface with Python built-in data structures and with the Python collections library.
Note that any contributed backends or extensions must include unit tests in backends/tests to demonstrate new Backend capability.
We will not accept pull requests that are not tested.
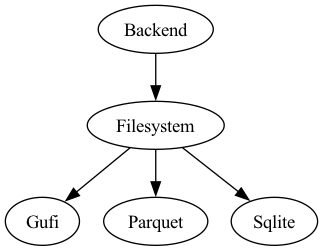
Figure depicts the current DSI backend class hierarchy.
Filesystem Backends
Filesystem backends enable a user to ingest data into a local database file, and to query that file for metadata. The database file is stored in the user’s local directory and is persistent across user sessions. DSI’s Filesystem backends support POSIX-enforced file permissions, so users can control access to their data.
SQLite
- class dsi.backends.sqlite.Sqlite(filename, **kwargs)
SQLite Filesystem Backend to which a user can ingest/process data, generate a Jupyter notebook, and find occurrences of a search term
- __init__(filename, **kwargs)
Initializes a SQLite backend with a user inputted filename, and creates other internal variables
- close()
Closes the SQLite database’s connection.
- display(table_name, num_rows=25, display_cols=None)
Returns all data from a specified table in this SQLite backend.
- table_namestr
Name of the table to display.
- num_rowsint, optional, default=25
Maximum number of rows to print. If the table contains fewer rows, only those are shown.
- display_colslist of str, optional
List of specific column names to display from the table.
If None (default), all columns are displayed.
- find(query_object)
Searches for all instances of query_object in the SQLite database at the table, column, and cell levels. Includes partial matches as well.
- query_objectint, float, or str
The value to search for across all tables in the backend.
- Returnlist
A list of ValueObjects representing matches.
Note: ValueObjects may vary in structure depending on whether the match occurred at the table, column, or cell level.
Refer to find_table(), find_column(), and find_cell() for the specific structure of each ValueObject type.
- find_cell(query_object, row=False)
Finds all cells in the database that match or partially match the given query_object.
- query_objectint, float, or str
The value to search for at the cell level, across all tables in the backend.
- row: bool, optional, default=False
If True, certain fields in ValueObject will contain entire row’s metadata/data If False, certain fields in ValueObject will only contain the matching cell’s metadata/data.
Return : List of ValueObjects if there is a match.
- ValueObject Structure:
t_name: table name (str)
c_name: list of column names.
If row=True: list of all column names in the table
If row=False: list with one element - the matched column name
value:
If row=True: full row of values
If row=False: value of the matched cell
row_num: row index of the match
type:
If row=True: ‘row’
If row=False: ‘cell’
- find_column(query_object, range=False)
Finds all columns whose names match or partially match the given query_object.
- query_objectstr
The string to search for in column names.
- rangebool, optional, default=False
If True, value in the returned ValueObject will be the [min, max] of the matching numerical column. If False, value in the returned ValueObject will be the full list of column data.
Return : List of ValueObjects if there is a match.
- ValueObject Structure:
t_name: table name (str)
c_name: list containing one element - the matching column name
value:
If range=True: [min, max]
If range=False: list of column data
row_num: None
type:
If range=True: ‘range’
If range=False: ‘column’
- find_relation(column_name, relation)
Finds all rows in the first table of the database that satisfy the relation applied to the given column.
- column_namestr
The name of the column to apply the relation to.
- relationstr
The operator and value to apply to the column. Ex: >4, <4, =4, >=4, <=4, ==4, !=4, (4,5), ~4, ~~4
- Returnlist of ValueObjects
One ValueObject per matching row in that first table.
- ValueObject Structure:
t_name: table name (str)
c_name: list of all columns in the table
value: full row of values
row_num: row index of the match
type: ‘relation’
- find_table(query_object)
Finds all tables whose names match or partially match the given query_object.
- query_objectstr
The string to search for in table names.
- Returnlist of ValueObjects
One ValueObject per matching table.
- ValueObject Structure:
t_name: table name (str)
c_name: list of all columns in the table
value: table data as list of rows (each row is a list)
row_num: None
type: ‘table’
- get_schema()
Returns the structural schema of this database in the form of CREATE TABLE statements.
- Return: str
Each table’s CREATE TABLE statement is concatenated into one large string.
- get_table(table_name, dict_return=False)
Retrieves all data from a specified table without requiring knowledge of SQL.
This method is a simplified alternative to query_artifacts() for users who are only familiar with Python.
- table_namestr
Name of the table in the SQLite backend.
- dict_returnbool, optional, default=False
If True, returns the result as an OrderedDict. If False, returns the result as a pandas DataFrame.
- Returnpandas.DataFrame or OrderedDict
If dict_return is False: returns a DataFrame
If dict_return is True: returns an OrderedDict
- get_table_names(query)
Extracts all table names from a SQL query. Helper function for query_artifacts() that users do not need to call
- querystr
A SQL query string, typically passed into query_artifacts().
- Return: list of str
List of table names referenced in the query.
- ingest_artifacts(collection, isVerbose=False)
Primary function to ingest a collection of tables into the defined SQLite database.
Creates the auto generated runTable if the corresponding flag was set to True when initializing a Core.Terminal Also creates a dsi_units table if any units are associated with the ingested data values.
Can only be called if a SQLite database is loaded as a BACK-WRITE backend. (See core.py for distinction between BACK-READ and BACK-WRITE.)
- collectionOrderedDict
A nested OrderedDict representing multiple tables and their associated data. Each top-level key is a table name, and its value is an OrderedDict of column names and corresponding data lists.
- isVerbosebool, optional, default=False
If True, prints all SQL insert statements during the ingest process for debugging or inspection purposes.
- ingest_table_helper(types, foreign_query=None, isVerbose=False)
Internal use only. Do not call
Helper function to create SQLite table based on a passed in schema.
- typesDataType
- A DataType-derived object that defines:
the table name as a string,
table properties as a dictionary mapping column names to data,
associated units for each column.
- foreign_querystr, optional, default=None
A valid SQL string specifying foreign key constraints to apply to the table.
- isVerbosebool, optional, default=False
If True, prints the CREATE TABLE statements for debugging or inspection.
- list(collection=False)
Return a list of all tables and their dimensions from this SQLite backend
- collectionbool, optional, default False.
If True, returns the list of table names.
If False (default), prints metadata of all the tables: table names and dimensions.
- notebook(interactive=False)
Generates a Jupyter notebook displaying all the data in the SQLite database.
If multiple tables exist, each is displayed as a separate DataFrame.
If database has table relations, it is stored as a separate dataframe. If database has a units table, each table’s units are stored in its corresponding dataframe attrs variable
interactive: default is False. When set to True, creates an interactive Jupyter notebook, otherwise creates an HTML file.
- num_tables()
Prints number of tables in this backend
- overwrite_table(table_name, collection)
Overwrites specified table(s) in this SQLite backend using the provided Pandas DataFrame(s).
If a relational schema has been previously loaded into the backend, it will be reapplied to the table. Note: This function permanently deletes the existing table and its data, before inserting the new data.
- table_namestr or list
If str, name of the table to overwrite in the backend.
If list, list of all tables to overwrite in the backend
- collectionpandas.DataFrame or list of Pandas.DataFrames
If one item, a DataFrame containing the updated data will be written to the table.
If a list, all DataFrames with updated data will be written to their own table
- process_artifacts(only_units_relations=False)
Reads data from the SQLite database into a nested OrderedDict. Keys are table names, and values are OrderedDicts containing table data.
If the database contains PK/FK relationships, they are stored in a special dsi_relations table.
- only_units_relationsbool, default=False
USERS SHOULD IGNORE THIS FLAG. Used internally by sqlite.py.
- ReturnOrderedDict
A nested OrderedDict containing all data from the SQLite database.
- query_artifacts(query, isVerbose=False, dict_return=False, **kwargs)
Executes a SQL query on the SQLite backend.
Supports: - SELECT / PRAGMA: returns DataFrame or OrderedDict depending on dict_return - UPDATE / ALTER: executes command and returns None
- querystr
Must be a SELECT or PRAGMA SQL query. Aggregate functions like COUNT are allowed. If dict_return is True, the query must target a single table and cannot include joins.
- isVerbosebool, optional, default=False
If True, prints the SQL SELECT statements being executed.
- dict_returnbool, optional, default=False
If True, returns the result as an OrderedDict. If False, returns the result as a pandas DataFrame.
- Returnpandas.DataFrame or OrderedDict or None
If query includes UPDATE or ALTER: returns nothing
If dict_return is False: returns a DataFrame
If dict_return is True: returns an OrderedDict
- sql_type(input_list)
Internal use only. Do not call
Evaluates a list and returns the predicted compatible SQLite Type
- input_listlist
A list of values to analyze for type compatibility.
- Return: str
A string representing the inferred SQLite data type for the input list.
- summary(table_name=None)
Returns numerical metadata from tables in the first activated backend.
- table_namestr, optional
If specified, only the numerical metadata for that table is returned as a Pandas DataFrame.
If None (default), names of all tables and metadata for each table is returned as a list. [table_name_list, table1_df, table2_df, table3df …]
- summary_helper(table_name)
Internal use only. Do not call
Generates and returns summary metadata for a specific table in the SQLite backend.
DuckDB
- class dsi.backends.duckdb.DuckDB(filename, **kwargs)
DuckDB Filesystem Backend to which a user can ingest/process data, generate a Jupyter notebook, and find occurrences of a search term
- __init__(filename, **kwargs)
Initializes a DuckDB backend with a user inputted filename, and creates other internal variables
- check_table_relations(tables, relation_dict)
Internal use only. Do not call.
Checks if a user-loaded schema has circular dependencies.
If no circular dependencies are found, returns a list of tables ordered from least dependent to most dependent, suitable for staged ingestion into the DuckDB backend.
Note: This method is intended for internal use only. DSI users should not call this directly.
- tableslist of str
List of table names to ingest into the DuckDB backend.
- relation_dictOrderedDict
An OrderedDict describing table relationships. Structured as the dsi_relations object with primary and foreign keys.
- Return: tuple of (has_cycle, ordered_tables)
has_cycle (bool): True if a circular dependency is detected.
ordered_tables (list or None): Ordered list of tables if no cycle is found; None if a circular dependency exists.
- close()
Closes the DuckDB database’s connection.
Return: None
- display(table_name, num_rows=25, display_cols=None)
Returns all data from a specified table in this DuckDB backend.
- table_namestr
Name of the table to display.
- num_rowsint, optional, default=25
Maximum number of rows to print. If the table contains fewer rows, only those are shown.
- display_colslist of str, optional
List of specific column names to display from the table.
If None (default), all columns are displayed.
- find(query_object)
Searches for all instances of query_object in the DuckDB database at the table, column, and cell levels. Includes partial matches as well.
- query_objectint, float, or str
The value to search for across all tables in the backend.
- Returnlist
A list of ValueObjects representing matches.
Note: ValueObjects may vary in structure depending on whether the match occurred at the table, column, or cell level.
Refer to find_table(), find_column(), and find_cell() for the specific structure of each ValueObject type.
- find_cell(query_object, row=False)
Finds all cells in the database that match or partially match the given query_object.
- query_objectint, float, or str
The value to search for at the cell level, across all tables in the backend.
- row: bool, optional, default=False
If True, certain fields in ValueObject will contain entire row’s metadata/data If False, certain fields in ValueObject will only contain the matching cell’s metadata/data.
Return : List of ValueObjects if there is a match.
- ValueObject Structure:
t_name: table name (str)
c_name: list of column names.
If row=True: list of all column names in the table
If row=False: list with one element - the matched column name
value:
If row=True: full row of values
If row=False: value of the matched cell
row_num: row index of the match
type:
If row=True: ‘row’
If row=False: ‘cell’
- find_column(query_object, range=False)
Finds all columns whose names match or partially match the given query_object.
- query_objectstr
The string to search for in column names.
- rangebool, optional, default=False
If True, value in the returned ValueObject will be the [min, max] of the matching numerical column. If False, value in the returned ValueObject will be the full list of column data.
Return : List of ValueObjects if there is a match.
- ValueObject Structure:
t_name: table name (str)
c_name: list containing one element - the matching column name
value:
If range=True: [min, max]
If range=False: list of column data
row_num: None
type:
If range=True: ‘range’
If range=False: ‘column’
- find_relation(column_name, relation)
Finds all rows in the first table of the database that satisfy the relation applied to the given column.
- column_namestr
The name of the column to apply the relation to.
- relationstr
The operator and value to apply to the column. Ex: >4, <4, =4, >=4, <=4, ==4, !=4, (4,5), ~4, ~~4
- Returnlist of ValueObjects
One ValueObject per matching row in that first table.
- ValueObject Structure:
t_name: table name (str)
c_name: list of all columns in the table
value: full row of values
row_num: row index of the match
type: ‘relation’
- find_table(query_object)
Finds all tables whose names match or partially match the given query_object.
- query_objectstr
The string to search for in table names.
- Returnlist of ValueObjects
One ValueObject per matching table.
- ValueObject Structure:
t_name: table name (str)
c_name: list of all columns in the table
value: table data as list of rows (each row is a list)
row_num: None
type: ‘table’
- get_schema()
Returns the structural schema of this database in the form of CREATE TABLE statements.
- Return: str
Each table’s CREATE TABLE statement is concatenated into one large string.
- get_table(table_name, dict_return=False)
Retrieves all data from a specified table without requiring knowledge of SQL.
This method is a simplified alternative to query_artifacts() for users who are only familiar with Python.
- table_namestr
Name of the table in the DuckDB backend.
- dict_returnbool, optional, default=False
If True, returns the result as an OrderedDict. If False, returns the result as a pandas DataFrame.
- Returnpandas.DataFrame or OrderedDict
If dict_return is False: returns a DataFrame
If dict_return is True: returns an OrderedDict
- get_table_names(query)
Extracts all table names from a SQL query. Helper function for query_artifacts() that users do not need to call
- querystr
A SQL query string, typically passed into query_artifacts().
- Return: list of str
List of table names referenced in the query.
- ingest_artifacts(collection, isVerbose=False)
Primary function to ingest a collection of tables into the defined DuckDB database.
Creates the auto generated runTable if the corresponding flag was set to True when initializing a Core.Terminal Also creates a dsi_units table if any units are associated with the ingested data values.
Cannot ingest data if it has a complex schema with circular dependencies, ex: A->B->C->A
Can only be called if a DuckDB database is loaded as a BACK-WRITE backend. (See core.py for distinction between BACK-READ and BACK-WRITE.)
- collectionOrderedDict
A nested OrderedDict representing multiple tables and their associated data. Each top-level key is a table name, and its value is an OrderedDict of column names and corresponding data lists.
- isVerbosebool, optional, default=False
If True, prints all SQL insert statements during the ingest process for debugging or inspection purposes.
- ingest_table_helper(types, foreign_query=None, isVerbose=False)
Internal use only. Do not call
Helper function to create DuckDB table based on a passed in schema.
- typesDataType
- A DataType-derived object that defines:
the table name as a string,
table properties as a dictionary mapping column names to data,
associated units for each column.
- foreign_querystr, optional, default=None
A valid SQL string specifying foreign key constraints to apply to the table.
- isVerbosebool, optional, default=False
If True, prints the CREATE TABLE statements for debugging or inspection.
- list(collection=False)
Return a list of all tables and their dimensions from this DuckDB backend
- collectionbool, optional, default False.
If True, returns the list of table names.
If False (default), prints metadata of all the tables: table names and dimensions.
- num_tables()
Prints number of tables in this backend
- overwrite_table(table_name, collection)
Overwrites specified table(s) in this DuckDB backend using the provided Pandas DataFrame(s).
If a relational schema has been previously loaded into the backend, it will be reapplied to the table. Cannot accept any schemas with circular dependencies.
Note: This function permanently deletes the existing table and its data, before inserting the new data.
- table_namestr or list
If str, name of the table to overwrite in the backend.
If list, list of all tables to overwrite in the backend
- collectionpandas.DataFrame or list of Pandas.DataFrames
If one item, a DataFrame containing the updated data will be written to the table.
If a list, all DataFrames with updated data will be written to their own table
- process_artifacts(only_units_relations=False)
Reads data from the DuckDB database into a nested OrderedDict. Keys are table names, and values are OrderedDicts containing table data.
If the database contains PK/FK relationships, they are stored in a special dsi_relations table.
- only_units_relationsbool, default=False
USERS SHOULD IGNORE THIS FLAG. Used internally by duckdb.py.
- ReturnOrderedDict
A nested OrderedDict containing all data from the DuckDB database.
- query_artifacts(query, isVerbose=False, dict_return=False, **kwargs)
Executes a SQL query on the DuckDB backend.
Supports: - SELECT / PRAGMA: returns DataFrame or OrderedDict depending on dict_return - UPDATE / ALTER: executes command and returns None
- querystr
Must be a SELECT or PRAGMA SQL query. Aggregate functions like COUNT are allowed. If dict_return is True, the query must target a single table and cannot include joins.
- isVerbosebool, optional, default=False
If True, prints the SQL SELECT statements being executed.
- dict_returnbool, optional, default=False
If True, returns the result as an OrderedDict. If False, returns the result as a pandas DataFrame.
- Returnpandas.DataFrame or OrderedDict or None
If query includes UPDATE or ALTER: returns nothing
If dict_return is False: returns a DataFrame
If dict_return is True: returns an OrderedDict
- sql_type(input_list)
Internal use only. Do not call
Evaluates a list and returns the predicted compatible DuckDB Type
- input_listlist
A list of values to analyze for type compatibility.
- Return: str
A string representing the inferred DuckDB data type for the input list.
- summary(table_name=None)
Returns numerical metadata from tables in the first activated backend.
- table_namestr, optional
If specified, only the numerical metadata for that table is returned as a Pandas DataFrame.
If None (default), names of all tables and metadata for each table is returned as a list. [table_name_list, table1_df, table2_df, table3df …]
- summary_helper(table_name)
Internal use only. Do not call
Generates and returns summary metadata for a specific table in the DuckDB backend.
GUFI
- class dsi.backends.gufi.Gufi(prefix, index, dbfile, table, column, verbose=False)
GUFI Datastore
- __init__(prefix, index, dbfile, table, column, verbose=False)
prefix: prefix to GUFI commands
index: directory with GUFI indexes
dbfile: sqlite db file from DSI
table: table name from the DSI db we want to join on
column: column name from the DSI db to join on
verbose: print debugging statements or not
- query_artifacts(query)
Retrieves GUFI’s metadata joined with a dsi database query: an sql query into the dsi_entries table
Webserver Backends
Webserver backends enable a user to connect to a remote data platform and interact with retrieved data in-memory.
NDP (Read-only)
NDP-CKAN Webserver Backend for DSI
Read-only backend that pulls metadata from CKAN-based NDP instances and exposes it as in-memory DSI tables: datasets and resources.
- class dsi.backends.ndp.NDP(url=None, params=None, **kwargs)
CKAN-based web backend for querying NDP metadata in-memory
- __init__(url=None, params=None, **kwargs)
Initialize backend and optionally load data from CKAN API.
- urlstr, optional
Base CKAN URL. If None, a default CKAN endpoint is used.
- paramsdict, optional
Dictionary of initial query parameters used to fetch data from CKAN.
- Supported keys:
keywords : str - Search keywords
organization : str - Organization name filter
tags : list - List of tags to filter by
formats : list - List of resource formats (e.g., [‘CSV’, ‘JSON’])
limit : int - Maximum number of datasets to retrieve (default: 100)
- **kwargsdict
Additional keyword arguments.
- api_keystr, optional
API key for authentication
- verify_sslbool, optional
Toggle SSL verification (default False)
- close()
Resets backend state and clears all cached data.
- display(table_name, num_rows=25, display_cols=None)
Displays rows from a specified table.
Accepts either dataset_title or dataset_id for resource tables.
- table_namestr
Title or ID of the table to display
- num_rowsint, default 25
Number of rows to display
- display_colslist of str, optional
Subset of columns to display
- Returnpandas.DataFrame
Displayed table data with long strings truncated
- find(query_object, **kwargs)
Searches for all instances of query_object across the table, column, and cell levels.
- query_objectint, float, or str
The value to search for across all tables in the backend
- **kwargsdict
Additional keyword arguments
- Returnlist of ValueObjects representing matches across:
table names
column names
cell values
- ValueObject Structure:
t_name : (str) Table name
c_name : (list) Column name(s)
row_num : (int or None) Row index
value : (any) Matched value or data
type : (str) {‘table’, ‘column’, ‘cell’}
- find_cell(query_object, **kwargs)
Finds all cells that match the given query_object.
Exact match for all data types, plus case-insensitive partial match for strings.
- query_objectint, float, or str
The value to search for within table cells
- **kwargsdict
Additional keyword arguments
- Returnlist of ValueObject
One ValueObject per matching cell
- ValueObject Structure:
t_name : (str) Table name
c_name : (list) List with the matched column name
row_num : (int) Row index of the match
value : (any) Matched cell value
type : (str) ‘cell’
- find_column(query_object, **kwargs)
Finds all columns whose names contain the given query_object. Search is case-insensitive.
- query_objectstr
The string to match against column names
- **kwargsdict
Additional keyword arguments
- Returnlist of ValueObject
One ValueObject per matching column
- ValueObject Structure:
t_name : (str) Table name
c_name : (list) List with the matched column name
value : (list) Full column data
row_num : (None)
type : (str) ‘column’
- find_relation(column_name, relation, **kwargs)
NDP is a read-only metadata backend and does not support relational queries on columns.
- find_table(query_object, **kwargs)
Finds all tables whose names contain the given query_object. Search is case-insensitive.
- query_objectstr
The string to match against table names
- **kwargsdict
Additional keyword arguments
- Returnlist of ValueObject
One ValueObject per matching table
- ValueObject Structure:
t_name : (str) Table name
c_name : (list) List of all columns in the table
value : (dict) Full table data (dict of columns)
row_num : (None)
type : (str) ‘table’
- get_schema()
Return a lightweight schema description of cached tables from CKAN.
- Returnstr
Each table’s structural schema is combined into one large string.
- get_table(table_name, dict_return=False)
Returns all data from a specified table.
- table_namestr
Dataset title or ID
- dict_returnbool, default False
If True, returns OrderedDict. If False, returns DataFrame.
Return : OrderedDict or pandas.DataFrame
- get_table_names(query)
Extracts table/dataset names mentioned in a query string.
- querystr
Query string to parse
- Returnlist
List of dataset names/IDs found in query
- ingest_artifacts(artifacts, **kwargs) None
Not supported - NDP backend is read-only
- list(collection=False)
Lists tables or prints each table’s dimensions.
For resource tables, displays both dataset_title and dataset_id.
- collectionbool, default False
If True, return list of table names.
If False, print table names with dimensions and dataset IDs.
- Returnlist or None
Table names if collection=True, otherwise None
- notebook(**kwargs)
Notebook generation not supported for NDP backend.
- num_tables()
Prints the number of tables (datasets) loaded.
- process_artifacts()
Returns all cached tables in tiered format:
{ "datasets": <dataset table>, "<dataset_name>": <resource table>, ... }
Useful for exporting or writing data to external formats.
- ReturnOrderedDict
All cached tables in tiered structure
- query_artifacts(query, dict_return=True, **kwargs)
Query all tables using a pandas query string.
- querystr
Pandas query string for filtering data
- dict_returnbool, optional, default True
If True, returns dict format. If False, returns pandas DataFrames.
- **kwargsdict
Additional keyword arguments
- Returndict
Dictionary mapping table names to query results
- summary(table_name=None)
Returns numerical metadata for tables. For resource tables, includes dataset_id information.
- table_namestr, optional
If provided, returns summary for a single table. Either dataset_title or dataset_id. If None, returns summary for all tables in expected format.
- Returnpandas.DataFrame or list
If table_name is None: returns [table_names_list, df1, df2, …]
If table_name provided: returns single DataFrame
- validate_connection()
Validates the connection to the base CKAN URL is reachable and CKAN API is responsive.
- Raises:
ConnectionError : If the URL cannot be reached
RuntimeError : If the CKAN API returns an error response
- Returnbool
True if connection is valid
- validate_urls()
Validates resource URLs across all resource tables.
Adds ‘url_valid’ boolean column to each resource table.
Oceans11 (Read-only)
Oceans11 Webserver Backend for DSI
Read-only backend that pulls metadata from DSI-based https://oceans11.lanl.gov data catalog and exposes it as in-memory DSI tables: datasets and resources.
- class dsi.backends.oceans11.Oceans11(url=None, params=None, **kwargs)
DSI-based web backend for querying Oceans11 metadata in-memory
- __init__(url=None, params=None, **kwargs)
Initialize backend and optionally load data from DSI databases.
- urlstr, optional
Base Oceans11 URL.
- paramsdict, optional
Dictionary of initial query parameters used to fetch data from OSTI.
- Supported keys:
“q”,
“keyword”,
“osti_id”,
“title”,
“authors”,
“doi”,
“report_number”,
“rows”
- **kwargsdict
Additional keyword arguments:
workspace : str, optional
- close()
Close Oceans11 backend and clear loaded state.
- display(table_name, num_rows=25, display_cols=None)
Displays rows from a specified Oceans11 table.
Accepts either dataset_title or dataset_id for resource tables.
- table_namestr
Name or ID of the table to display
- num_rowsint, default 25
Number of rows to display
- display_colslist of str, optional
Subset of columns to display
- Returnpandas.DataFrame
Displayed table data with long strings truncated
- find(query_object, **kwargs)
Searches for all instances of query_object across the table, column, and cell levels.
- query_objectint, float, or str
The value to search for across all tables in the backend
- **kwargsdict
Additional keyword arguments
- Returnlist of ValueObjects representing matches across:
table names
column names
cell values
- ValueObject Structure:
t_name : (str) Table name
c_name : (list) Column name(s)
row_num : (int or None) Row index
value : (any) Matched value or data
type : (str) {‘table’, ‘column’, ‘cell’}
- find_cell(query_object, row=False, **kwargs)
Finds all cells that match the given query_object.
Exact match for all data types, plus case-insensitive partial match for strings.
- query_objectint, float, or str
The value to search for within table cells
- row: bool, optional, default=False
If True, certain fields in ValueObject will contain entire row’s metadata/data If False, certain fields in ValueObject will only contain the matching cell’s metadata/data.
- **kwargsdict
Additional keyword arguments
- Returnlist of ValueObject
One ValueObject per matching cell
- ValueObject Structure:
t_name : (str) Table name
c_name : (list) All columns in table (row=True) or just matched column name (row=False)
row_num : (int) Row index of the match
value : (any) full row of values (row=True) or just matched cell value (row=False)
type : (str) ‘row’ (row=True) or ‘cell’ (row=False)
- find_column(query_object, **kwargs)
Finds all columns whose names contain the given query_object. Search is case-insensitive.
- query_objectstr
The string to match against column names
- **kwargsdict
Additional keyword arguments
- Returnlist of ValueObject
One ValueObject per matching column
- ValueObject Structure:
t_name : (str) Table name
c_name : (list) List with the matched column name
value : (list) Full column data
row_num : (None)
type : (str) ‘column’
- find_relation(column_name, relation, **kwargs)
Finds all rows in the ‘records’ table that satisfy the relation on the given column.
- column_namestr
The name of the column to apply the relation to.
- relationstr
The operator and value to apply to the column. Ex: >4, <4, =4, >=4, <=4, ==4, !=4
- Returnlist of ValueObjects
One ValueObject per matching row in that first table.
- ValueObject Structure:
t_name: (str) table name
c_name: (list) list of all columns in the table
value: (list) full row of values
row_num: (int) row index of the match
type: (str) ‘relation’
- find_table(query_object, **kwargs)
Finds all tables whose names contain the given query_object. Search is case-insensitive.
- query_objectstr
The string to match against table names
- **kwargsdict
Additional keyword arguments
- Returnlist of ValueObject
One ValueObject per matching table
- ValueObject Structure:
t_name : (str) Table name
c_name : (list) List of all columns in the table
value : (dict) Full table data (dict of columns)
row_num : (None)
type : (str) ‘table’
- get_schema()
Return a lightweight schema description of cached tables from CKAN.
- Returnstr
Each table’s structural schema is combined into one large string.
- get_table(table_name, dict_return=False)
Returns all data from a specified table.
- table_namestr
Dataset title or ID
- dict_returnbool, default False
If True, returns OrderedDict. If False, returns DataFrame.
Return : OrderedDict or pandas.DataFrame
- get_table_names(query)
Extracts table/dataset names mentioned in a query string.
- querystr
Query string to parse
- Returnlist
List of dataset names/IDs found in query
- ingest_artifacts(artifacts, **kwargs) None
Not supported - Oceans11 backend is read-only
- list(collection=False)
Lists tables or prints each table’s dimensions.
- collectionbool, default False
If True, return list of table names.
If False, print table names with dimensions.
- Returnlist or None
Table names if collection=True, otherwise None
- notebook(**kwargs)
Notebook generation not supported for Oceans11 backend.
- num_tables()
Prints the number of cached tables.
- process_artifacts()
Return selected Tier 1 Oceans11 records for export/process.
Tier 2 databases remain separate local files and are referenced through the t2db_path column.
- ReturnOrderedDict
Exportable Tier 1 records table
- query_artifacts(query, dict_return=True, **kwargs)
Query all tables using a pandas query string.
- querystr
Pandas query string for filtering data
- dict_returnbool, optional, default True
If True, returns dict format. If False, returns pandas DataFrames.
- **kwargsdict
Additional keyword arguments
- Returndict
Dictionary mapping table names to query results
- summary(table_name=None)
Returns numerical metadata for tables. For resource tables, includes dataset_id information.
- table_namestr, optional
If provided, returns summary for a single table. Either dataset_title or dataset_id. If None, returns summary for all tables in expected format.
- Returnpandas.DataFrame or list
If table_name is None: returns [table_names_list, df1, df2, …]
If table_name provided: returns single DataFrame
- validate_connection()
Validates that the base Oceans11 URL is accessible and functional.
- Tests the connection by calling DSI Federated’s pull_data() to:
Download the oceans11.db catalog from https://oceans11.lanl.gov/dataCatalog/
Set self.catalog_path to the download location
- Raises:
ConnectionError : If online catalog is inaccessible or pull_data failed
RuntimeError : If the downloaded catalog is corrupt or inaccessible
- Returnbool
True if connection is valid
OSTI (Read-only)
OSTI Backend for DSI
Read-only access that pulls metadata from REST-based OSTI backend and exposes it as an in-memory DSI table: records
- class dsi.backends.osti.OSTI(url=None, params=None, **kwargs)
REST-based web backend for querying OSTI metadata in-memory
- __init__(url=None, params=None, **kwargs)
Initialize backend and optionally load data from REST API.
- urlstr, optional
Base OSTI URL. If None, a default OSTI endpoint is used.
- paramsdict, optional
Dictionary of initial query parameters used to fetch data from OSTI.
- Supported keys:
“q”,
“osti_id”,
“doi”,
“fulltext”,
“biblio”,
“author”,
“title”,
“identifier”,
“sponsor_org”,
“research_org”,
“contributing_org”,
“source_id”,
“publication_date_start”,
“publication_date_end”,
“entry_date_start”,
“entry_date_end”,
“language”,
“country”,
“site_ownership_code”,
“subject”,
“has_fulltext”,
“sort”,
“order”,
“rows”,
“page”,
- **kwargsdict
Additional keyword arguments.
- api_keystr, optional
API key for authentication
- verify_sslbool, optional
Toggle SSL verification (default False)
- close()
Reset backend state and clear cached data.
- display(table_name='records', num_rows=25, display_cols=None)
Displays rows from the ‘records’ table.
- table_namestr, optional, default = ‘records’
Name of the table to display
- num_rowsint, default 25
Number of rows to display
- display_colslist of str, optional
Subset of columns to display
- Returnpandas.DataFrame
Displayed table data with long strings truncated
- find(query_object, **kwargs)
Searches for all instances of query_object across the table, column, and cell levels.
- query_objectint, float, or str
The value to search for across all tables in the backend
- **kwargsdict
Additional keyword arguments
- Returnlist of ValueObjects representing matches across:
table names
column names
cell values
- ValueObject Structure:
t_name : (str) Table name
c_name : (list) Column name(s)
row_num : (int or None) Row index
value : (any) Matched value or data
type : (str) {‘table’, ‘column’, ‘cell’}
- find_cell(query_object, **kwargs)
Finds all cells that match the given query_object.
Exact match for all data types, plus case-insensitive partial match for strings.
- query_objectint, float, or str
The value to search for within table cells
- **kwargsdict
Additional keyword arguments
- Returnlist of ValueObject
One ValueObject per matching cell
- ValueObject Structure:
t_name : (str) Table name
c_name : (list) List with the matched column name
row_num : (int) Row index of the match
value : (any) Matched cell value
type : (str) ‘cell’
- find_column(query_object, **kwargs)
Finds all columns whose names contain the given query_object. Search is case-insensitive.
- query_objectstr
The string to match against column names
- **kwargsdict
Additional keyword arguments
- Returnlist of ValueObject
One ValueObject per matching column
- ValueObject Structure:
t_name : (str) Table name
c_name : (list) List with the matched column name
value : (list) Full column data
row_num : (None)
type : (str) ‘column’
- find_relation(column_name, relation, **kwargs)
Relation finding is not supported for the OSTI backend.
- find_table(query_object, **kwargs)
Finds all tables whose names contain the given query_object. Search is case-insensitive.
- query_objectstr
The string to match against table names
- **kwargsdict
Additional keyword arguments
- Returnlist of ValueObject
One ValueObject per matching table
- ValueObject Structure:
t_name : (str) Table name
c_name : (list) List of all columns in the table
value : (dict) Full table data (dict of columns)
row_num : (None)
type : (str) ‘table’
- get_schema()
Return a lightweight schema description of cached tables from OSTI.
- Returnstr
Each table’s structural schema is combined into one large string.
- get_table(table_name='records', dict_return=False)
Returns all data from the ‘records’ table
- table_namestr, optional, default=’records’
table_name must be ‘records’ or None
- dict_returnbool, default False
If True, returns OrderedDict. If False, returns DataFrame.
Return : OrderedDict or pandas.DataFrame
- get_table_names(query)
Extracts table/dataset names mentioned in a query string.
- querystr
Query string to parse
- Returnlist
List of dataset names/IDs found in query
- ingest_artifacts(artifacts, **kwargs) None
Ingest is not supported for the OSTI backend.
- list(collection=False)
Lists tables or prints each table’s dimensions.
- collectionbool, default False
If True, return list of table names.
If False, print table names with dimensions.
- Returnlist or None
Table names if collection=True, otherwise None
- notebook(**kwargs)
Notebook generation not supported for OSTI backend.
- num_tables()
Prints the number of tables (datasets) loaded.
- process_artifacts()
Returns all cached OSTI data:
{ "records": <records table> }
Useful for exporting or writing data to external formats.
- ReturnOrderedDict
Cached records table
- query_artifacts(query, dict_return=True, **kwargs)
Query all tables using pandas.query()
- querystr
Pandas query string for filtering data
- dict_returnbool, optional, default True
If True, returns dict format. If False, returns pandas DataFrames.
- **kwargsdict
Additional keyword arguments
- Returndict
Dictionary mapping table names to query results
- summary(table_name=None)
Returns numerical metadata for the cached ‘records’ table.
- table_namestr, optional
If provided or not, returns summary for the ‘records’ table.
- Returnpandas.DataFrame or list
If table_name is None: returns [[‘records’], records_df]
If table_name provided: returns single DataFrame for records table
- validate_connection()
Validates that the base OSTI URL is accessible and functional.
- Tests the connection by making an API call to verify:
URL is reachable
API responds with valid JSON
Response format is a list of records
- Returnbool
True if connection is valid False if connection is invalid
- validate_urls()
Validate URL fields in the records table.
- Adds boolean columns indicating whether each URL is reachable:
citation_url_valid
citation_doe_pages_url_valid
fulltext_url_valid