DSI Readers/Writers
Readers/Writers connect data-producing applications to DSI core functionalities. A Reader function deals with existing data files or input streams. A Writer function deals with generating new data formats.
Readers/Writers are modular to support user contribution and contributors are encouraged to offer custom Readers/Writers abstract classes and implementations. A contributed Reader/Writer abstract class may either extend another Reader/Writer to inherit the properties of the parent, or be a completely new structure.
In order to be compatible with DSI, Readers should store data in data structures sourced from the Python collections library (OrderedDict).
Similarly, Writers should be compatible by accepting data structures from Python collections (OrderedDict) to export data/generate an image.
Any contributed Readers/Writers, or extension of one, should include unit tests in plugins/tests to demonstrate the new capability.
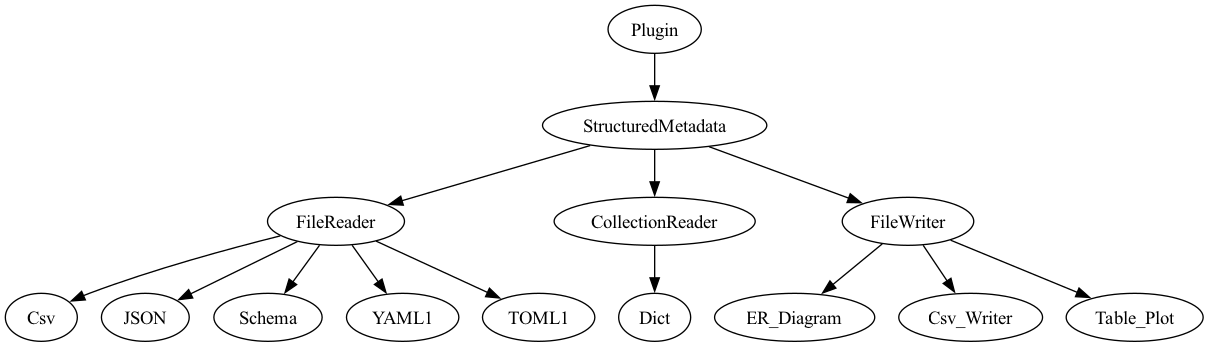
Figure depicts prominent portion of the current DSI Readers/Writers class hierarchy.
- class dsi.plugins.plugin.Plugin(path)
Plugin abstract class for DSI core product.
A Plugin connects a data reader or writer to a compatible middleware data structure.
- abstractmethod __init__(path)
Initialize Plugin setup.
Read a Plugin file. Return a Plugin object.
- abstractmethod add_to_output(path)
Initialize Plugin setup.
Read a Plugin file. Return a Plugin object.
Metadata Processing
Note for users: StructuredMetadata class is used to assign data from a file_reader to the DSI abstraction in core.
If data in a user-written reader is structured as an OrderedDict, only need to call set_schema_2() at the end of the reader’s add_rows()
- class dsi.plugins.metadata.StructuredMetadata(**kwargs)
plugin superclass that provides handy methods for structured data
- __init__(**kwargs)
Initializes StructuredMetadata class with an output collector (Ordered Dictionary)
- add_to_output(row: list, tableName=None) None
Old function to be deprecated soon. Do not use.
Adds a row of data to the output_collector with enforced structure.
This method is typically used within a plugin’s add_rows() method to incrementally build table output in a consistent format.
- rowlist
A single row of data to be added. Must match the expected structure for the target table.
- tableNamestr, optional
Name of the table to which the row should be added. If None, the function identifies which plugin called it and assigns tableName for that data
- schema_is_set() bool
Old function to be deprecated soon. Do not use.
Helper method to see if the schema has been set
- set_schema(table_data: list, validation_model=None) None
Old function to be deprecated soon. Do not use.
Initializes column structure in the output_collector and table_cnt.
This method is typically used within a plugin pack_header() method to define the expected schema before rows are added.
- table_datalist
Defines the table structure to be used.
- For multple-table data:
A list of tuples, each structured as (table_name, list_of_column_names)
- For single-table data:
A simple list of column names.
- set_schema_2(collection, validation_model=None) None
Use this if data in a Reader’s ``add_rows()`` is structured as an OrderedDict()
Faster update of the DSI abstraction when input data is structured as an OrderedDict.
This method is optimized for plugins where add_rows() passes data as an OrderedDict, and avoids the incremental row ingest via set_schema() and
add_to_output().- collectionOrderedDict
The plugin’s data structure (with data) passed from a plugin.
If collection only contains one table, the data will be wrapped in another OrderedDict, where the plugin’s class name is the table name key.
File Readers
- Note for users:
DSI assumes data structure from all data sources are consistent/stable. Ex: table/column names MUST be consistent. Number of columns in a table CAN vary.
DSI Readers can handle data files with mismatched number of columns. Ex: file1: table1 has columns a, b, c. file2: table1 has columns a, b, d
if only reading in one table at a time, users can utilize python pandas to stack mulutiple dataframes vertically (ex: CSV reader)
if multiple tables in a file, users must pad tables with null values (ex: YAML1, which has example code at bottom of
add_rows()to implement this)
- class dsi.plugins.file_reader.Bueno(filenames, **kwargs)
A DSI Reader that captures performance data from Bueno (github.com/lanl/bueno)
Bueno outputs performance data in keyvalue pairs in a file. Keys and values are delimited by
:. Keyval pairs are delimited by\n.- __init__(filenames, **kwargs) None
filenames: one Bueno file or a list of Bueno files to be ingested
- add_rows() None
Parses Bueno data and adds a list containing 1 or more rows.
- class dsi.plugins.file_reader.Cloverleaf(folder_path, **kwargs)
DSI Reader that stores input and output Cloverleaf data from a directory for each simulation run
- __init__(folder_path, **kwargs)
- folder_pathstr
Filepath to the directory where the Cloverleaf data is stored. The directory should have a subfolder for each simulation run, each containing input and output data
- add_rows() None
Flattens data from each simulation’s input file as a row in the input table. Flattens data from each simulation’s output file as a row in the output table. Creates a simulation table which is stores each simulation’s number and execution datetime.
- return: None.
If an error occurs, a tuple in the format - (ErrorType, “error message”) - is returned to and printed by the core
- class dsi.plugins.file_reader.Csv(filenames, table_name=None, **kwargs)
A DSI Reader that reads in CSV data
- __init__(filenames, table_name=None, **kwargs)
Initializes the CSV Reader with user specified filenames and optional table_name.
- filenamesstr or list of str
Required. One or more CSV file paths to be loaded into DSI. If multiple files are provided, all data must correspond to the same table.
- table_namestr, optional
Optional name to assign to the loaded table. If not provided, DSI will default to using “Csv” as the table name.
- add_rows() None
Adds a list containing one or more rows of the CSV along with file_info to output.
- class dsi.plugins.file_reader.DublinCoreDatacard(filenames, **kwargs)
DSI Reader that stores a dataset’s data card as a row in the dublin_core_datacard table. Input datacard should follow template in examples/test/template_dc_dublin_core.xml
- __init__(filenames, **kwargs)
- filenamesstr or list of str
File name(s) of XML data card files to ingest. Each file must adhere to the Dublin Core metadata standard.
- add_rows() None
Flattens data in the input data card as a row in the dublin_core_datacard table
- return: None.
If an error occurs, a tuple in the format - (ErrorType, “error message”) - is returned to and printed by the core
- class dsi.plugins.file_reader.Ensemble(filenames, table_name=None, sim_table=True, **kwargs)
DSI Reader that loads ensemble simulation data stored in a CSV file.
Designed to handle simulation outputs where each row represents an individual simulation run. Specifically for single-run use cases when data is post-processed.
Automatically generates a simulation metadata table to accompany the data.
- __init__(filenames, table_name=None, sim_table=True, **kwargs)
Initializes Ensemble Reader with user specified parameters.
- filenamesstr or list of str
Required input. One or more Ensemble data files in CSV format. All files must correspond to the same table.
- table_namestr, optional
Optional name to assign to the table when loading the Ensemble data. If not provided, the default table name, ‘Ensemble’, will be used.
- sim_tablebool, default=True
If True, creates a simulation metadata table (sim_table) where each row in the input data table represents a separate simulation run.
Adds a new column to the input data to associate each row with its corresponding entry in the simulation table.
If False, skips creation of the simulation table.
- add_rows() None
Creates an OrderedDict representation of the Ensemble data to load into DSI.
When sim_table = True, a sim_table Ordered Dict is created alongside the Ensemble data table OrderedDict. Both tables are nested within a larger OrderedDict.
- return: None.
If an error occurs, a tuple in the format - (ErrorType, “error message”) - is returned to and printed by the core
- class dsi.plugins.file_reader.GoogleDatacard(filenames, **kwargs)
DSI Reader that stores a dataset’s data card as a row in the google_datacard table. Input datacard should follow template in examples/test/template_dc_google.yml
- __init__(filenames, **kwargs)
- filenamesstr or list of str
File name(s) of YAML data card files to ingest. Each file must adhere to the Google Data Cards Playbook metadata standard.
- add_rows() None
Flattens data in the input data card as a row in the google_datacard table
- return: None.
If an error occurs, a tuple in the format - (ErrorType, “error message”) - is returned to and printed by the core
- class dsi.plugins.file_reader.JSON(filenames, table_name=None, **kwargs)
A DSI Reader for ingesting generic JSON data with flat key-value pairs.
This reader assumes that all values are primitive data types (e.g., str, int, float), and that there are no nested dictionaries, arrays, or complex structures.
The keys in the JSON object are treated as column names, and their corresponding values are interpreted as rows.
- __init__(filenames, table_name=None, **kwargs) None
Initializes the generic JSON reader with user-specified filenames
- filenamesstr or list of str
Required input. One or more JSON file paths to be loaded into DSI. If multiple files are provided, all data must all correspond to the same table
- table_namestr, optional
Name to assign to the loaded table. If not provided, DSI defaults to using “JSON” as the table name.
- add_rows() None
Parses JSON data and stores data into a table as an Ordered Dictionary.
- class dsi.plugins.file_reader.MetadataReader1(filenames, target_table_prefix=None, **kwargs)
DSI Reader that reads in an individual or a set of JSON metadata files
- __init__(filenames, target_table_prefix=None, **kwargs)
filenames: one metadata json file or a list of metadata json files to be ingested
target_table_prefix: prefix to be added to every table created to differentiate between other metadata file sources
- add_rows() None
Parses metadata json files and creates an ordered dict whose keys are file names and values are an ordered dict of that file’s data
- class dsi.plugins.file_reader.Oceans11Datacard(filenames, **kwargs)
DSI Reader that stores a dataset’s data card as a row in the oceans11_datacard table. Input datacard should follow template in examples/test/template_dc_oceans11.yml
- __init__(filenames, **kwargs)
- filenamesstr or list of str
File name(s) of YAML data card files to ingest. Each file must adhere to the Oceans 11 LANL Data Server metadata standard.
- add_rows() None
Flattens data in the input data card as a row in the oceans11_datacard table
- return: None.
If an error occurs, a tuple in the format - (ErrorType, “error message”) - is returned to and printed by the core
- class dsi.plugins.file_reader.Schema(filename, target_table_prefix=None, **kwargs)
DSI Reader for parsing and ingesting a relational schema alongside its associated data.
Schema file input should be a JSON file that defines primary and foreign key relationships between tables in a data source. Parsed relationships are stored in the global dsi_relations table, which is used for creating backends and used by writers.
This reader is essential when working with complex, multi-table data structures. See Cloverleaf (Complex Schemas) to learn how a schema file should be structured
- __init__(filename, target_table_prefix=None, **kwargs)
Initializes the Schema reader with the specified schema file.
- filename: str
Path to the JSON file containing the schema to be ingested. This file should define primary and foreign key relationships between tables.
- target_table_prefixstr, optional
A prefix to prepend to every table name in the primary and foreign key lists. Useful for avoiding naming conflicts in shared environments.
- add_rows() None
Generates a dsi_relations OrderedDict to be added to the internal DSI abstraction.
The Ordered Dict has 2 keys, primary key and foreign key, with their values a list of PK and FK tuples associating tables and columns
- class dsi.plugins.file_reader.SchemaOrgDatacard(filenames, **kwargs)
DSI Reader that stores a dataset’s data card as a row in the schema_org_datacard table. Input datacard should follow template in examples/test/template_dc_schema_org.json
- __init__(filenames, **kwargs)
- filenamesstr or list of str
File name(s) of JSON data card files to ingest. Each file must adhere to the Schema.org metadata standard.
- add_rows() None
Flattens data in the input data card as a row in the schema_org_datacard table
- return: None.
If an error occurs, a tuple in the format - (ErrorType, “error message”) - is returned to and printed by the core
- class dsi.plugins.file_reader.TOML1(filenames, target_table_prefix=None, **kwargs)
DSI Reader that reads in an individual or a set of TOML files
Table names are the keys for the main ordered dictionary and column names are the keys for each table’s nested ordered dictionary
- __init__(filenames, target_table_prefix=None, **kwargs)
- filenamesstr or list of str
One TOML file or a list of TOML files to be loaded into DSI.
- target_table_prefix: str, optional
A prefix to be added to each table name created from the TOML data. Useful for distinguishing between tables from other data sources.
- add_rows() None
Parses TOML data and constructs a nested OrderedDict to load into DSI.
The resulting structure has:
Top-level keys as table names.
Each value is an OrderedDict where:
Keys are column names.
Values are lists representing column data.
- return: None.
If an error occurs, a tuple in the format - (ErrorType, “error message”) - is returned to and printed by the core
- class dsi.plugins.file_reader.YAML1(filenames, target_table_prefix=None, yamlSpace=' ', **kwargs)
DSI Reader that reads in an individual or a set of YAML files
Table names are the keys for the main ordered dictionary and column names are the keys for each table’s nested ordered dictionary
- __init__(filenames, target_table_prefix=None, yamlSpace=' ', **kwargs)
Initializes the YAML1 reader with the specified YAML file(s)
- filenamesstr or list of str
One YAML file or a list of YAML files to be loaded into DSI.
- target_table_prefix: str, optional
A prefix to be added to each table name created from the YAML data. Useful for distinguishing between tables from other data sources.
- yamlSpacestr, default=’ ‘
The indentation used in the input YAML files. Defaults to two spaces, but can be customized to match the formatting in certain files.
- add_rows() None
Parses YAML data and constructs a nested OrderedDict to load into DSI.
The resulting structure has:
Top-level keys as table names.
Each value is an OrderedDict where:
Keys are column names.
Values are lists representing column data.
- return: None.
If an error occurs, a tuple in the format - (ErrorType, “error message”) - is returned to and printed by the core
File Writers
- Note for users:
DSI’s runTable is only included in File Writers if data was previously ingested into a backend in a Core.Terminal workflow where runTable was set to True.
Ex: in Example 5: Process and Write data, runTable is included in a generated ER Diagram since it uses ingested data from Example 2: Ingest data where runTable = True
- class dsi.plugins.file_writer.Csv_Writer(table_name, filename, export_cols=None, **kwargs)
DSI Writer to output queries as CSV data
- __init__(table_name, filename, export_cols=None, **kwargs)
Initializes the CSV Writer with the specified inputs
- table_namestr
Name of the table to export from the DSI backend.
- filenamestr
Name of the CSV file to be generated.
- export_colslist of str, optional, default is None.
A list of column names to include in the exported CSV file.
If None , all columns from the table will be included.
Ex: if a table has columns [a, b, c, d, e], and export_cols = [a, c, e], only those are writted to the CSV
- get_rows(collection) None
Exports data from the given DSI data collection to a CSV file.
- collectionOrderedDict
- The internal DSI abstraction. This is a nested OrderedDict where:
Top-level keys are table names.
Each value is another OrderedDict representing the table’s data (with column names as keys and lists of values).
- return: None.
If an error occurs, a tuple in the format - (ErrorType, “error message”) - is returned to and printed by the core
- class dsi.plugins.file_writer.ER_Diagram(filename, target_table_prefix=None, **kwargs)
DSI Writer that generates an ER Diagram from the current data in the DSI abstraction
- __init__(filename, target_table_prefix=None, **kwargs)
Initializes the ER Diagram writer
- filenamestr
File name for the generated ER diagram. Supported formats are .png, .pdf, .jpg, or .jpeg.
- target_table_prefixstr, optional
If provided, filters the ER Diagram to only include tables whose names begin with this prefix.
Ex: If prefix = “student”, only “student__address”, “student__math”, “student__physics” tables are included
- get_rows(collection) None
Generates the ER Diagram from the given DSI data collection.
- collectionOrderedDict
- The internal DSI abstraction. This is a nested OrderedDict where:
Top-level keys are table names.
Each value is another OrderedDict representing the table’s data (with column names as keys and lists of values).
- return: None.
If an error occurs, a tuple in the format - (ErrorType, “error message”) - is returned to and printed by the core
- class dsi.plugins.file_writer.Table_Plot(table_name, filename, display_cols=None, **kwargs)
DSI Writer that plots all numeric column data for a specified table
- __init__(table_name, filename, display_cols=None, **kwargs)
Initializes the Table Plot writer with specified inputs
- table_namestr
Name of the table to plot
- filenamestr
Name of the output file where the generated plot will be saved.
- display_cols: list of str, optional, default is None.
A list of column names to include in the plot. All included columns must contain numerical data.
If None (default), all numerical columns in the specified table will be plotted.
- get_rows(collection) None
Generates a plot of a specified table from the given DSI data collection.
- collectionOrderedDict
- The internal DSI abstraction. This is a nested OrderedDict where:
Top-level keys are table names.
Each value is another OrderedDict representing the table’s data (with column names as keys and lists of values).
- return: None.
If an error occurs, a tuple in the format - (ErrorType, “error message”) - is returned to and printed by the core
Environment Plugins
- class dsi.plugins.env.Environment
Environment Plugins inspect the calling process’ context.
Environments assume a POSIX-compliant filesystem and always collect UID/GID information.
- __init__()
Initializes StructuredMetadata class with an output collector (Ordered Dictionary)
- class dsi.plugins.env.GitInfo(git_repo_path='./')
A Plugin to capture Git information.
Adds the current git remote and git commit to metadata.
- __init__(git_repo_path='./') None
Initializes the git repo in the given directory and access to git commands
- add_rows() None
Adds a row to the output with POSIX info, git remote, and git commit
- pack_header() None
Set schema with POSIX and Git columns
- class dsi.plugins.env.Hostname(**kwargs)
An example Environment implementation.
This plugin collects the hostname of the machine, and couples this with the POSIX information gathered by the Environment base class.
- __init__(**kwargs) None
Initializes StructuredMetadata class with an output collector (Ordered Dictionary)
- add_rows() None
Parses environment provenance data and adds the row.
- pack_header() None
Set schema with keys of prov_info.
- class dsi.plugins.env.SystemKernel
Plugin for reading environment provenance data.
An environment provenance plugin which does the following:
System Kernel Version
Kernel compile-time config
Kernel boot config
Kernel runtime config
Kernel modules and module config
Container information, if containerized
- __init__() None
Initialize SystemKernel with inital provenance info.
- add_rows() None
Parses environment provenance data and adds the row.
- static get_cmd_output(cmd: list, ignore_stderr=False) str
Runs a given command and returns the stdout if successful.
If stderr is not empty, an exception is raised with the stderr text.
- get_kernel_bt_config() dict
Kernel boot-time configuration is collected by looking at /proc/cmdline.
The output of this command is one string of boot-time parameters. This string is returned in a dict.
- get_kernel_ct_config() dict
Kernel compile-time configuration is collected by looking at /boot/config-(kernel version) and removing comments and empty lines.
The output of said command is newline-delimited option=value pairs.
- get_kernel_mod_config() dict
Kernel module configuration is collected with the “lsmod” and “modinfo” commands.
Each module and modinfo are stored as a key-value pair in the returned dict.
- get_kernel_rt_config() dict
Kernel run-time configuration is collected with the “sysctl -a” command.
The output of this command is lines consisting of two possibilities: option = value (note the spaces), and sysctl: permission denied … The option = value pairs are added to the output dict.
- get_kernel_version() dict
Kernel version is obtained by the “uname -r” command, returns it in a dict.
- get_prov_info() str
Collect and return the different categories of provenance info.
- pack_header() None
Set schema with keys of prov_info.
Optional Plugin Type Enforcement
Plugins take data in an arbitrary format, and transform it into metadata which is queriable in DSI. Plugins may enforce types, but they are not required to enforce types.
Plugin type enforcement can be static, like the Hostname default plugin. Plugin type enforcement can also be dynamic, like the Bueno default plugin.
A collection of pydantic models for Plugin schema validation
- class dsi.plugins.plugin_models.EnvironmentModel(*, uid: int, effective_gid: int, moniker: str, gid_list: list[int])
- model_computed_fields: ClassVar[dict[str, ComputedFieldInfo]] = {}
A dictionary of computed field names and their corresponding ComputedFieldInfo objects.
- model_config: ClassVar[ConfigDict] = {}
Configuration for the model, should be a dictionary conforming to [ConfigDict][pydantic.config.ConfigDict].
- model_fields: ClassVar[dict[str, FieldInfo]] = {'effective_gid': FieldInfo(annotation=int, required=True), 'gid_list': FieldInfo(annotation=list[int], required=True), 'moniker': FieldInfo(annotation=str, required=True), 'uid': FieldInfo(annotation=int, required=True)}
Metadata about the fields defined on the model, mapping of field names to [FieldInfo][pydantic.fields.FieldInfo].
This replaces Model.__fields__ from Pydantic V1.
- class dsi.plugins.plugin_models.GitInfoModel(*, uid: int, effective_gid: int, moniker: str, gid_list: list[int], git_remote: str, git_commit: str)
- model_computed_fields: ClassVar[dict[str, ComputedFieldInfo]] = {}
A dictionary of computed field names and their corresponding ComputedFieldInfo objects.
- model_config: ClassVar[ConfigDict] = {}
Configuration for the model, should be a dictionary conforming to [ConfigDict][pydantic.config.ConfigDict].
- model_fields: ClassVar[dict[str, FieldInfo]] = {'effective_gid': FieldInfo(annotation=int, required=True), 'gid_list': FieldInfo(annotation=list[int], required=True), 'git_commit': FieldInfo(annotation=str, required=True), 'git_remote': FieldInfo(annotation=str, required=True), 'moniker': FieldInfo(annotation=str, required=True), 'uid': FieldInfo(annotation=int, required=True)}
Metadata about the fields defined on the model, mapping of field names to [FieldInfo][pydantic.fields.FieldInfo].
This replaces Model.__fields__ from Pydantic V1.
- class dsi.plugins.plugin_models.HostnameModel(*, uid: int, effective_gid: int, moniker: str, gid_list: list[int], hostname: str)
- model_computed_fields: ClassVar[dict[str, ComputedFieldInfo]] = {}
A dictionary of computed field names and their corresponding ComputedFieldInfo objects.
- model_config: ClassVar[ConfigDict] = {}
Configuration for the model, should be a dictionary conforming to [ConfigDict][pydantic.config.ConfigDict].
- model_fields: ClassVar[dict[str, FieldInfo]] = {'effective_gid': FieldInfo(annotation=int, required=True), 'gid_list': FieldInfo(annotation=list[int], required=True), 'hostname': FieldInfo(annotation=str, required=True), 'moniker': FieldInfo(annotation=str, required=True), 'uid': FieldInfo(annotation=int, required=True)}
Metadata about the fields defined on the model, mapping of field names to [FieldInfo][pydantic.fields.FieldInfo].
This replaces Model.__fields__ from Pydantic V1.
- class dsi.plugins.plugin_models.SystemKernelModel(*, uid: int, effective_gid: int, moniker: str, gid_list: list[int], kernel_info: str)
- model_computed_fields: ClassVar[dict[str, ComputedFieldInfo]] = {}
A dictionary of computed field names and their corresponding ComputedFieldInfo objects.
- model_config: ClassVar[ConfigDict] = {}
Configuration for the model, should be a dictionary conforming to [ConfigDict][pydantic.config.ConfigDict].
- model_fields: ClassVar[dict[str, FieldInfo]] = {'effective_gid': FieldInfo(annotation=int, required=True), 'gid_list': FieldInfo(annotation=list[int], required=True), 'kernel_info': FieldInfo(annotation=str, required=True), 'moniker': FieldInfo(annotation=str, required=True), 'uid': FieldInfo(annotation=int, required=True)}
Metadata about the fields defined on the model, mapping of field names to [FieldInfo][pydantic.fields.FieldInfo].
This replaces Model.__fields__ from Pydantic V1.
- dsi.plugins.plugin_models.create_dynamic_model(name: str, col_names: list[str], col_types: list[type], base=None) BaseModel
Creates a pydantic model at runtime with given name, column names and types, and an optional base model to extend.
This is useful for when column names are not known until they are retrieved at runtime.