4. Parthenon-VIBE
This is the documentation for the ATS-5 Benchmark, Parthenon-VIBE.
4.1. Purpose
The Parthenon-VIBE benchmark [Parthenon-VIBE] solves the Vector Inviscid Burgers’ Equation on a block-AMR mesh. This benchmark is configured to use three levels of mesh resolution and mesh blocks of size 16^3. This AMR configuration is meant to mimic applications which require high resolution, the ability to capture sharp and dynamic interfaces, while balancing global memory footprint and the overhead of “ghost” cells. This configuration should not be changed as it would violate the intent of the benchmark.
4.1.1. Problem
The benchmark performance problem solves
and evolves one or more passive scalar quantities \(q^i\) according to
as well as computing an auxiliary quantity \(d\) that resemebles a kinetic energy
Parthenon-VIBE makes use of a Godunov-type finite volume scheme with options for slope-limited linear or WENO5 reconstruction, HLL fluxes, and second order Runge-Kutta time integration.
4.1.2. Figure of Merit
The Figure of Merit is defined as cell zone-cycles / wallsecond which is the number of AMR zones processed per second of execution time.
4.2. Building
Accessing the sources
Clone the submodule from the benchmarks repository checkout
cd <path to benchmarks>
git submodule update --init --recursive
cd parthenon
Build requirements:
CMake 3.16 or greater
C++17 compatible compiler
Kokkos 3.6 or greater
MPI
To build Parthenon on CPU, including this benchmark, with minimal external dependencies, start here:
parthenon$ mkdir build && cd build
build$ cmake -DPARTHENON_DISABLE_HDF5=ON -DPARTHENON_ENABLE_PYTHON_MODULE_CHECK=OFF -DREGRESSION_GOLD_STANDARD_SYNC=OFF -DPARTHENON_ENABLE_TESTING=OFF -DCMAKE_BUILD_TYPE=Release ../
build$ make -j
On Crossroads the relevant modules for the results shown here are:
intel-classic/2023.2.0 cray-mpich/8.1.25
To build for execution on a single GPU, it should be sufficient to add flags similar to the CMake configuration line
cmake -DKokkos_ENABLE_CUDA=ON -DKokkos_ARCH_HOPPER90=ON
where Kokkos_ARCH should be set appropriately for the machine (see [here](https://kokkos.github.io/kokkos-core-wiki/keywords.html)).
4.3. Running
The benchmark includes an input file _burgers.pin_ that specifies the base (coarsest level) mesh size, the size of a mesh block, the number of levels, and a variety of other parameters that control the behavior of Parthenon and the benchmark problem configuration.
The executable burgers-benchmark will be built in parthenon/build/benchmarks/burgers/ and can be run as, e.g.
Note that the
NX=128
NXB=16
NLIM=250
NLVL=3
mpirun -np 112 burgers-benchmark -i ../../../benchmarks/burgers/burgers.pin parthenon/mesh/nx{1,2,3}=${NX} parthenon/meshblock/nx{1,2,3}=${NXB} parthenon/time/nlim=${NLIM} parthenon/mesh/numlevel=${NLVL}"
#srun -n 112 ... also works. Note that mpirun does not exist on HPE machines at LANL.
Varying the parthenon/mesh/nx* parameters will change the memory footprint. The memory footprint scales roughly as the product of parthenon/mesh/nx1, parthen/mesh/nx2, and parthenon/mesh/nx3. The parthen/meshblock/nx* parameters select the granularity of refinement: the mesh is distributed accross MPI ranks and refined/de-refined in chunks of this size.
For this benchmark only the parthenon/mesh/nx* parameters may be changed.
parthenon/mesh/nx1 must be evenly divisible by parthenon/meshblock/nx1 and the same for the other dimensions. Smaller meshblock sizes mean finer granularity and a problem that can be broken up accross more cores. However, each meshblock carries with it some overhead, so smaller meshblock sizes may hinder performance.
The results presented here use 128 and 160 for memory footprints of approximate 40%, and 60% respectively. These problem sizes are run with 8, 32, 56, 88, and 112 processes on a single node without threading.
Results from Parthenon are provided on the following systems:
Crossroads (see ATS-3/Crossroads)
A Grace Hopper (Grace ARM CPU 72 cores with 120GB, H100 GPU with 96GB)
The mesh and meshblock size parameters are chosen to balance
realism/performance with memory footprint. For the following tests we
examine memory footprints of 20%, 40%, and 60%. Memory was measured
using the tool parse_spatter_top.py found in this repository. It
was independently verified with the [Kokkos Tools Memory High Water
Mark](https://github.com/kokkos/kokkos-tools/wiki/MemoryHighWater)
tool. Increasing the parthenon/mesh/nx* parameters will increase the
memory footprint.
Included with this repository under utils/parthenon is a do_strong_scaling_cpu.sh
script, which takes one argument, specifying the desired memory
footprint on a system with 128GB system memory. Running it will generate a csv file
containing scaling numbers.
Also included with this respository under doc/sphinx/03_vibe/scaling/scripts/weak_scale_cpu_threads.sh
4.3.1. Crossroads
No. Cores |
Actual |
Ideal |
|---|---|---|
8 |
3.40e+06 |
3.40e+06 |
32 |
1.19e+07 |
1.36e+07 |
56 |
1.88e+07 |
2.38e+07 |
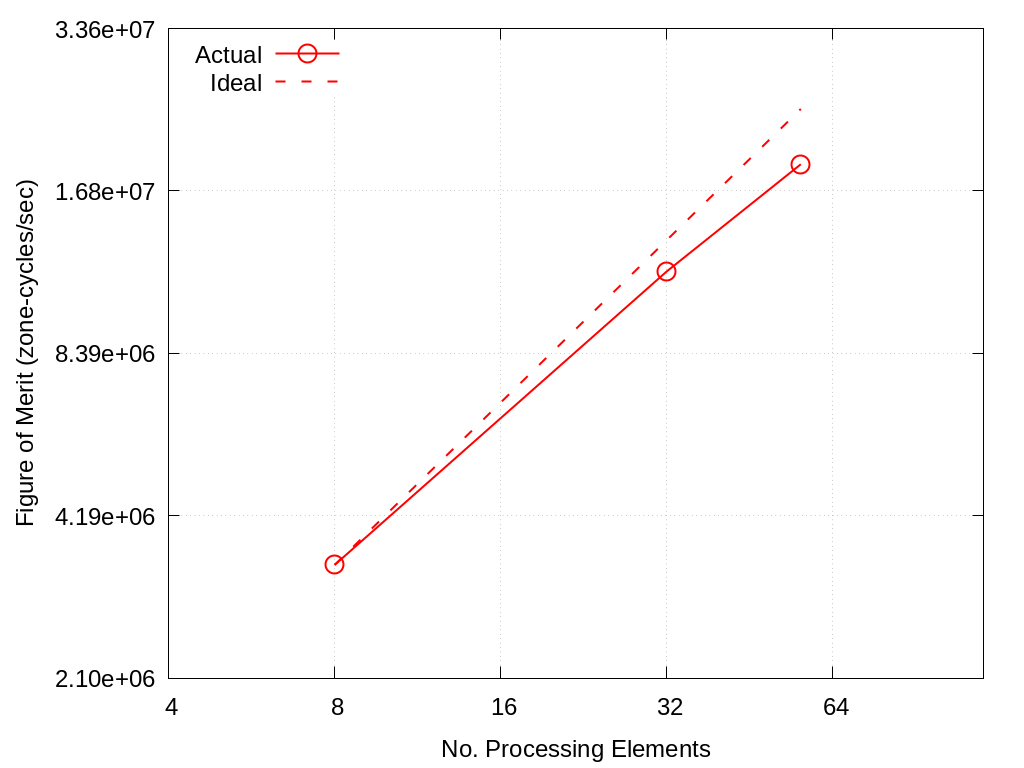
Fig. 4.1 VIBE Throughput Performance on Crossroads using ~20% Memory
No. Cores |
Actual |
Ideal |
|---|---|---|
8 |
2.80e+06 |
2.80e+06 |
32 |
1.12e+07 |
1.12e+07 |
56 |
1.79e+07 |
1.96e+07 |
88 |
2.36e+07 |
3.08e+07 |
112 |
2.61e+07 |
3.92e+07 |
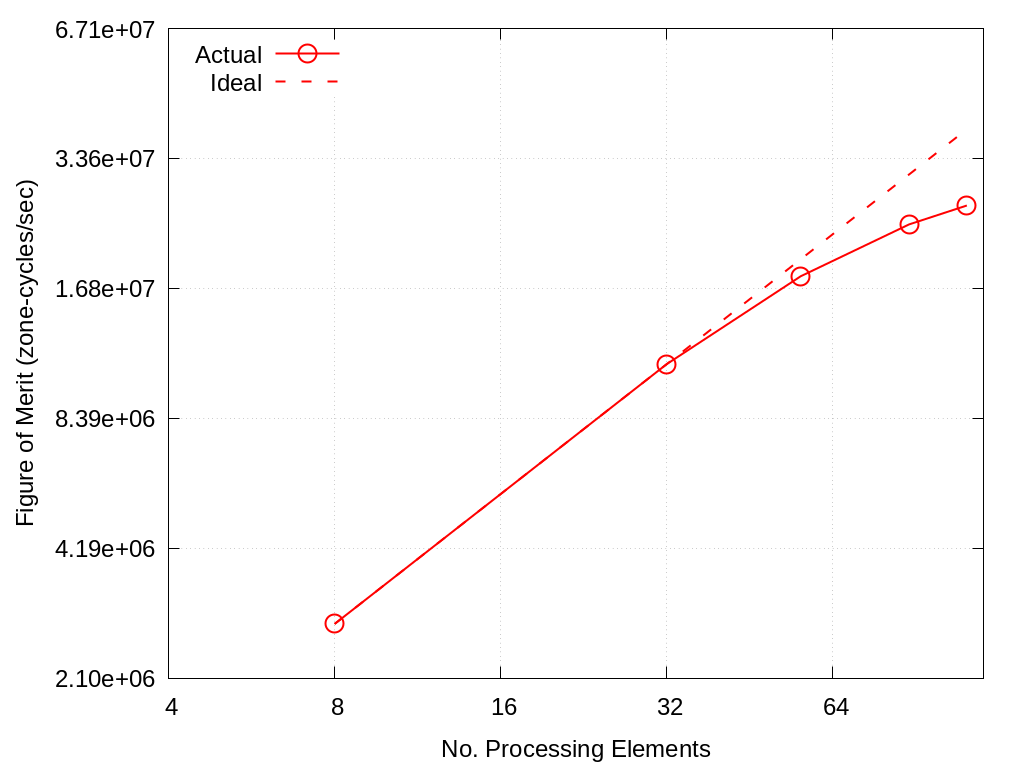
Fig. 4.2 VIBE Throughput Performance on Crossroads using ~40% Memory
No. Cores |
Actual |
Ideal |
|---|---|---|
8 |
2.40e+06 |
2.40e+06 |
32 |
9.56e+06 |
9.60e+06 |
56 |
1.54e+07 |
1.68e+07 |
88 |
2.16e+07 |
2.64e+07 |
112 |
2.44e+07 |
3.36e+07 |
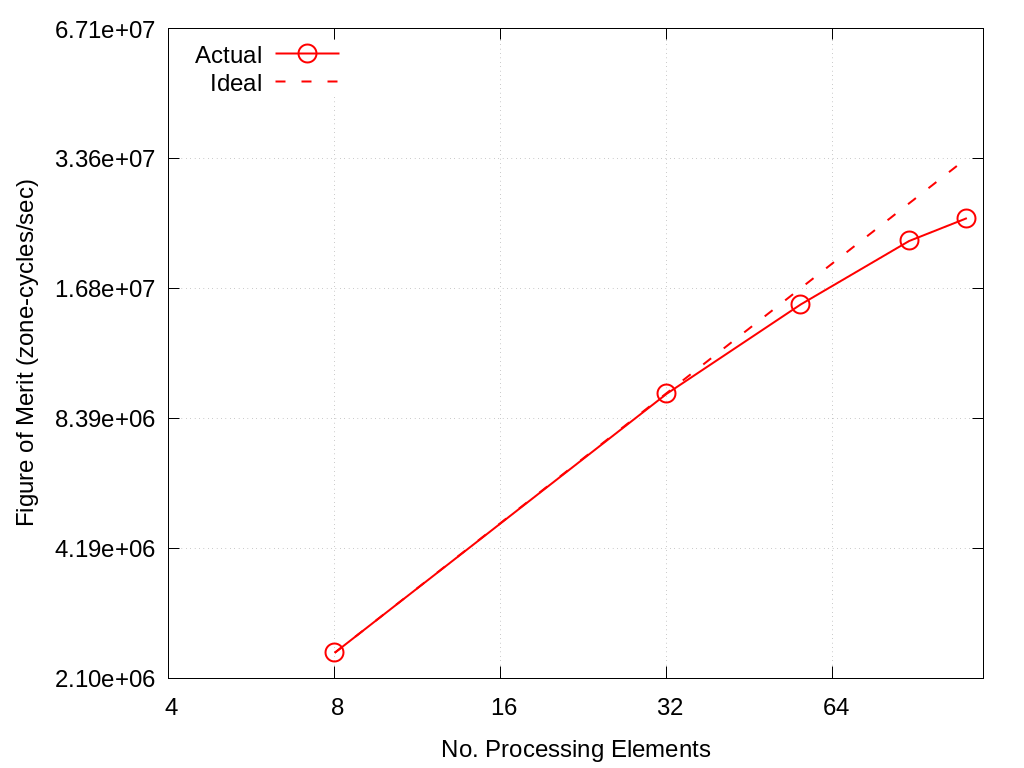
Fig. 4.3 VIBE Throughput Performance on Crossroads using ~60% memory
4.3.2. Nvidia Grace Hopper
Throughput performance of Parthenon-VIBE on a 96 GB H100 is provided within the following table and figure.
Mesh Base Size |
Actual |
|---|---|
32 |
2.88e+07 |
64 |
2.19e+07 |
96 |
1.41e+07 |
128 |
1.36e+07 |
160 |
1.03e+07 |
192 |
0 |
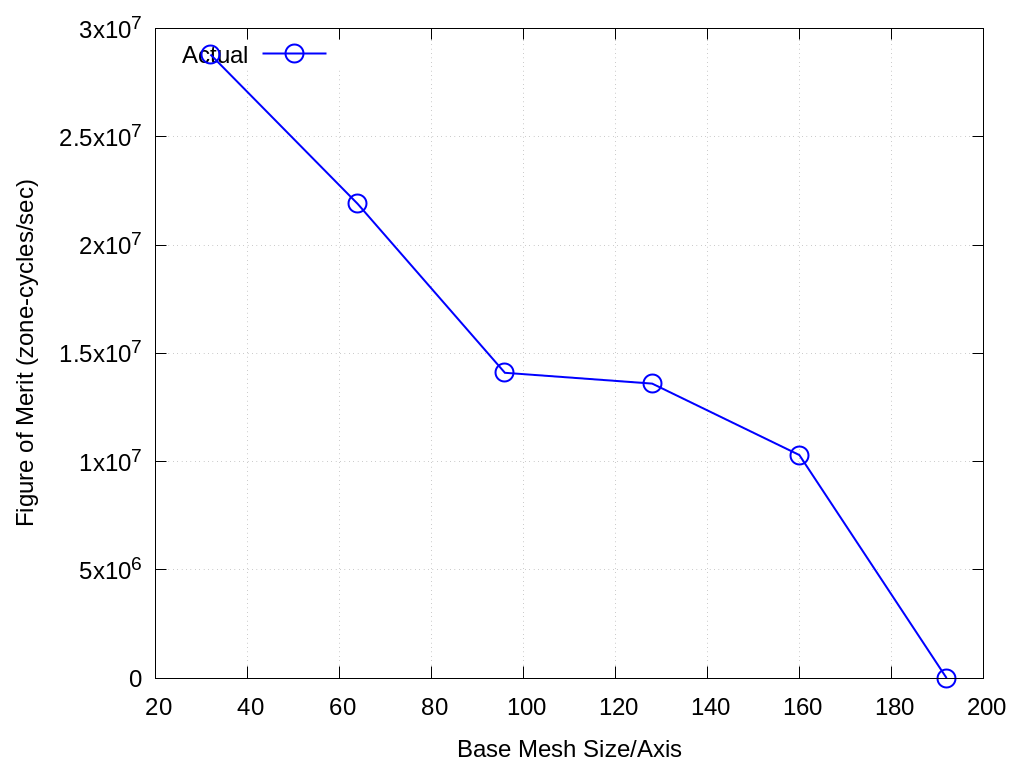
Fig. 4.4 VIBE Throughput Performance on H100
4.4. Multi-node scaling on Crossroads
The results of the scaling runs performed on Crossroads are presented below. Parthenon was built with intel oneapi 2023.1.0 and cray-mpich 8.1.25. These runs used between 4 and 4096 nodes with 8 ranks per node and 14 threads per rank (using Kokkos OpenMP) with the following problem sizes.
NXs=(256 320 400 512 640 800 1024 1280 1616 2048 2576) NODES=(4 8 16 32 64 128 256 512 1024 2048 4096)
Output files can be found in ./docs/sphinx/03_vibe/scaling/output/
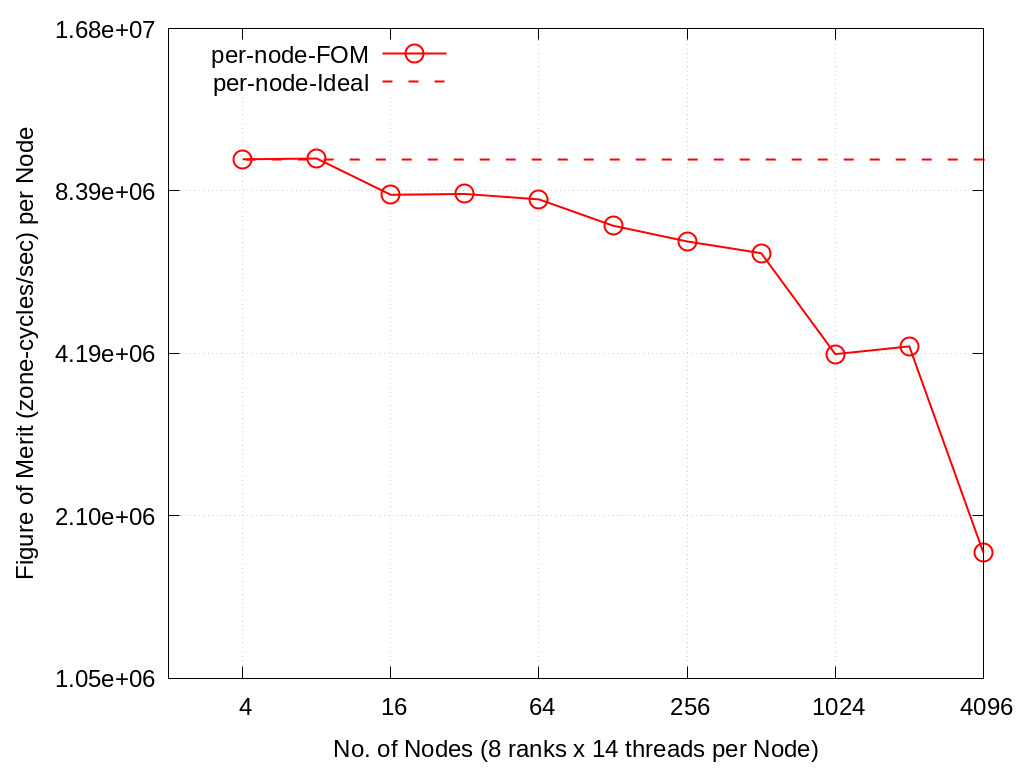
Nodes |
aggregate-FOM |
per-node-FOM |
per-node-Ideal |
|---|---|---|---|
4096 |
7.33E+09 |
1.79E+06 |
9.60E+06 |
2048 |
8.85E+09 |
4.32E+06 |
9.60E+06 |
1024 |
4.28E+09 |
4.18E+06 |
9.60E+06 |
512 |
3.29E+09 |
6.43E+06 |
9.60E+06 |
256 |
1.73E+09 |
6.76E+06 |
9.60E+06 |
128 |
9.26E+08 |
7.23E+06 |
9.60E+06 |
64 |
5.18E+08 |
8.09E+06 |
9.60E+06 |
32 |
2.65E+08 |
8.28E+06 |
9.60E+06 |
16 |
1.32E+08 |
8.25E+06 |
9.60E+06 |
8 |
7.70E+07 |
9.63E+06 |
9.60E+06 |
4 |
3.84E+07 |
9.60E+06 |
9.60E+06 |
Timings were captured using Caliper and are presented below.
Caliper files can be found in ./doc/sphinx/03_vibe/scaling/plots/Caliper
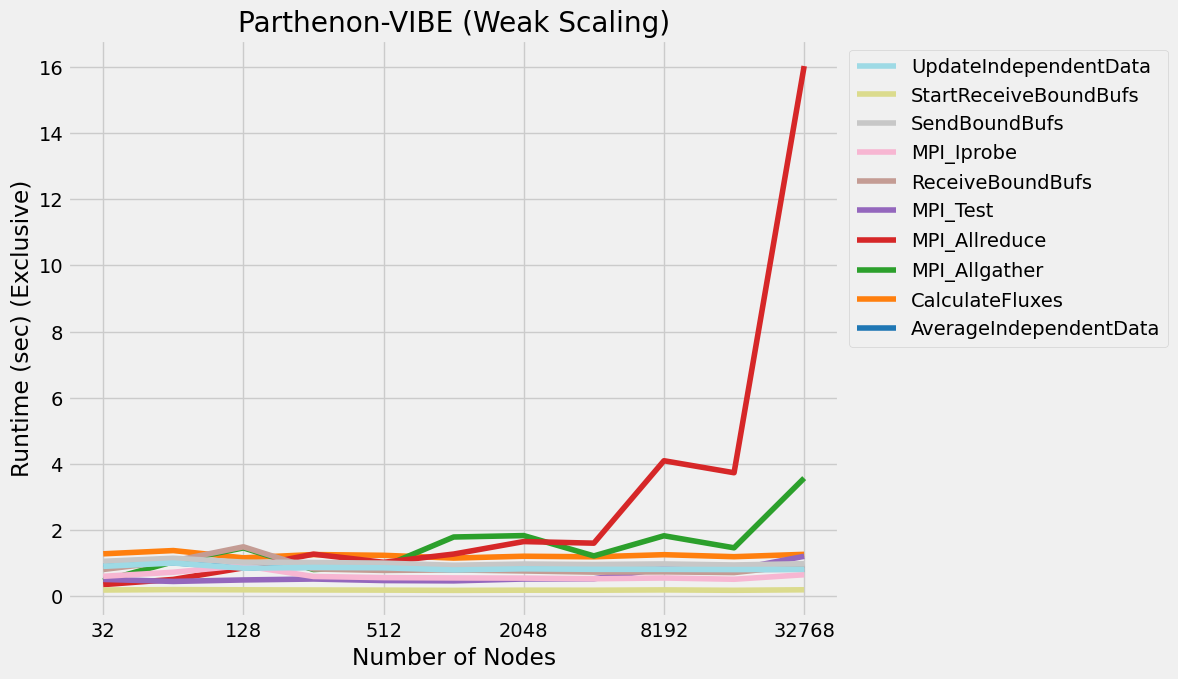
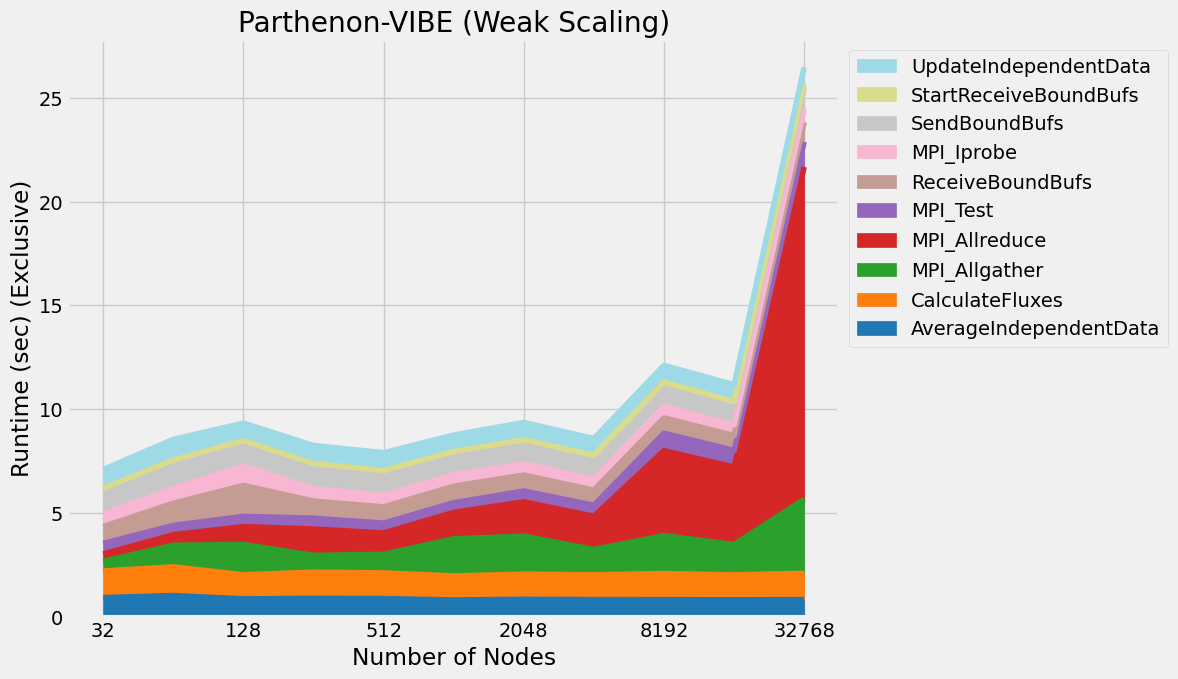
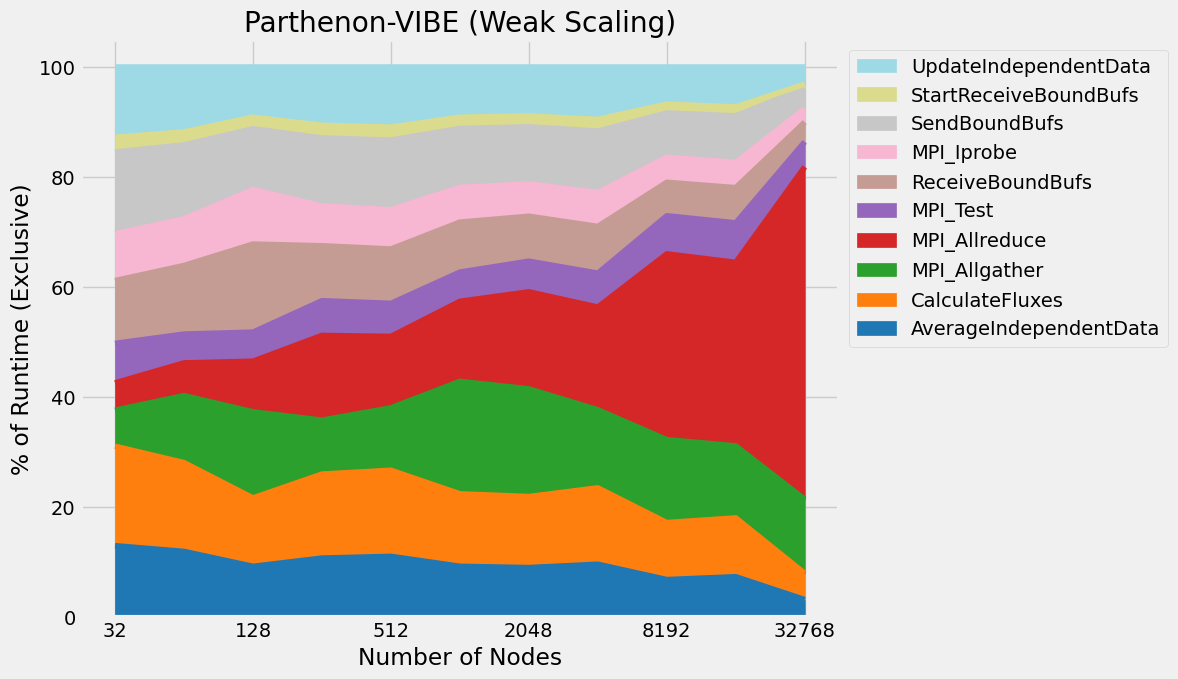
4.5. Validation
Parthenon-VIBE prints to a history file (default name burgers.hst) a
time series of the sum of squares of evolved variables integrated over
volume for each octant of the domain, as well as the total number of
meshblocks in the simulation at that time. To compare these quantities
between runs, we provide the burgers_diff.py program in the
benchmark folder. This will diff two history files and report when the
relative difference is greater than some tolerance.
Note
burgers.hst is appended to when the executable is re-run. So
if you want to compare two different history files, rename the
history file by changing either problem_id in the parthenon/job
block in the input deck (this can be done on the command line. When
you start the program, add parthenon/job/problem_id=mynewname to
the command line argument), or copy the old file to back it up.
To check that a modified calculation is still correct, run
burgers_diff.py to compare a new run to the fiducial one at the
default tolerance. If no diffs are reported, the modified calculation
is correct.
4.6. References
Jonah Miller, ‘Parthenon’, 2024. [Online]. Available: https://github.com/parthenon-hpc-lab/parthenon. [Accessed: 06- Feb- 2024]