6. DGEMM
6.1. Purpose
The DGEMM benchmark measures the sustained floating-point rate of a single node.
Benchmarks https://github.com/lanl/benchmarks/tree/main/microbenchmarks/dgemm
6.2. Characteristics
DGEMM is available in the benchmarks repository:
LANL Benchmarks: Benchmarks
6.2.1. Problem
Where \(A B C\) are square \(NxN\) vectors and \(\alpha\) and \(\beta\) are scalars. This operation is repeated \(R\) times.
6.2.2. Figure of Merit
The Gigaflops per second rate reported at the end of the run
GFLOP/s rate: <FOM> GF/s
6.2.3. Run Rules
Vendors are permitted to change the source code in the region marked in the source.
Optimized BLAS/DGEMM routines are permitted (and encouraged) to demonstrate the highest performance.
Vendors may modify the Makefile(s) as required
6.3. Building
Load the compiler; make and enter a build directory.
cmake -DBLAS_NAME=<blas library name> -DBLAS_ROOT=<root path to blas library> ..
make
Current BLAS_NAME options are mkl, cblas (openblas), essl, libsci, libsci_acc, cublas, cublasxt or the raw coded (OpenMP threaded) dgemm. The BLAS_NAME argument is required. If the headers or libraries aren’t found provide BLAS_LIB_DIR or BLAS_INCLUDE_DIR to cmake. If using a different blas library, modify the C source file to use the correct header and dgemm command.
6.4. Running
DGEMM uses OpenMP but does not use MPI.
Set the number of OpenMP threads and other OMP characteristics with export. The following were used for the Crossroads (ATS-3/Crossroads) system.
export OPENBLAS_NUM_THREADS=<nthreads> #MKL INHERITS FROM OMP_NUM_THREADS.
export OMP_NUM_THREADS=<nthreads>
export OMP_PLACES=cores
export OMP_PROC_BIND=close
./mt-dgemm <N> <R> <alpha> <beta>
These values default to: \(N=256, R=8, \alpha=1.0, \beta=1.0\)
These inputs are subject to the conditions \(N>128, R>4\).
These are positional arguments, so, for instance, R cannot be set without setting N.
6.5. Example Results
Results from DGEMM are provided on the following systems:
Crossroads (see ATS-3/Crossroads)
6.5.1. Crossroads
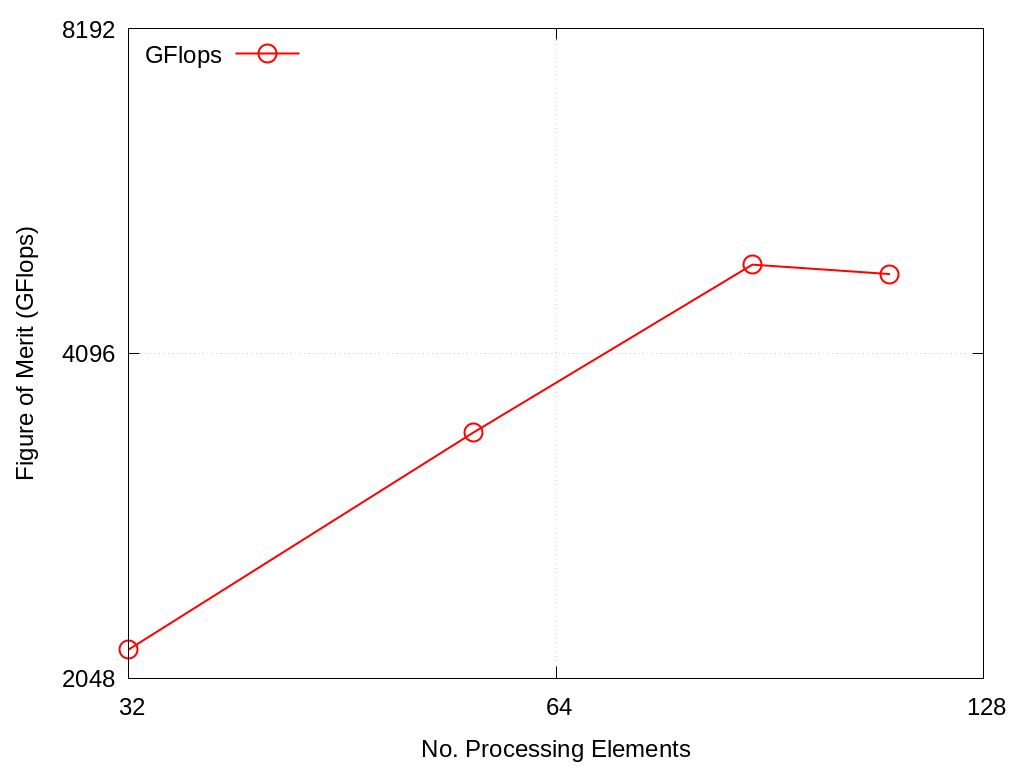
This test was built with the intel 2023.1.0 compiler using the crayOS compiler wrapper where: \(N=2500, R=500, \alpha=1.0, \beta=1.0\). The 110 core run (cores are used as OpenMP threads) avoids the OS dedicated cores and takes roughly an hour. All four runs on rocinante hbm take 5-6 hours.
No. Cores |
GFlops |
|---|---|
32 |
2176.5 |
56 |
3460.0 |
88 |
4949.1 |
110 |
4850.5 |