2. STREAM
2.1. Purpose
The STREAM benchmark is a widely used benchmark for measuring memory bandwidth. It measures the sustainable memory bandwidth of a computer system by performing simple read and write operations on large arrays.
2.2. Characteristics
STREAM is available in the benchmarks repository.
LANL Benchmarks: Benchmarks
2.2.1. Problem
There are four memory operations that the STREAM benchmark measures: Copy, Scale, Add, and Triad.
Copy - Copies data from one array to another:
Scale - Multiplies each array element by a constant, a daxpy operation.
Add - Adds two arrays element-wise:
Triad - Multiply-add operation:
These operations stress memory and floating point pipelines.They test memory transfer speed, computation speed, and different combinations of these two components of overall performance performance.
2.2.2. Figure of Merit
The primary FOM is the MAX Triad rate (MB/s).
2.2.3. Run Rules
The program must synchronize between each operation. For instance:
On a heterogeneous system, run stream for all computational devices. Where there is unified or heterogeneously addressable memory, also provide performance numbers for each device’s access to available memory types.
For instance: On a heterogenous node architecture with multi-core CPU with HBM2 memory and a GPU with HBM3 memory Stream performance should be reported for: CPU <-> HBM2, GPU <-> HBM3, CPU <-> HBM3, GPU <-> HBM2
Present CPU data as it scales with as a function of cores. It is acceptable to simply present the maximum bandwidth on GPUs/accelerators. More descriptive statistics are acceptable and welcome.
2.3. Building
Adjustments to GOMP_CPU_AFFINITY may be necessary.
The STREAM_ARRAY_SIZE value is a critical parameter set at compile time and controls the size of the array used to measure bandwidth. STREAM requires different amounts of memory to run on different systems, depending on both the system cache size(s) and the granularity of the system timer.
You should adjust the value of STREAM_ARRAY_SIZE to meet ALL of the following criteria:
Each array must be at least 4 times the size of the available cache memory. In practice the minimum array size is about 3.8 times the cache size. 1. Example 1: One Xeon E3 with 8 MB L3 cache
STREAM_ARRAY_SIZEshould be>= 4 million, giving an array size of 30.5 MB and a total memory requirement of 91.5 MB. 2. Example 2: Two Xeon E5’s with 20 MB L3 cache each (using OpenMP)STREAM_ARRAY_SIZEshould be>= 20 million, giving an array size of 153 MB and a total memory requirement of 458 MB.The size should be large enough so that the ‘timing calibration’ output by the program is at least 20 clock-ticks. For example, most versions of Windows have a 10 millisecond timer granularity. 20 “ticks” at 10 ms/tic is 200 milliseconds. If the chip is capable of 10 GB/s, it moves 2 GB in 200 msec. This means the each array must be at least 1 GB, or 128M elements.
The value
24xSTREAM_ARRAY_SIZExRANKS_PER_NODEmust be less than the amount of RAM on a node. STREAM creates 3 arrays of doubles; that is where 24 comes from. Each rank has 3 of these arrays.
Set STREAM_ARRAY_SIZE using the -D flag on your compile line.
The formula for STREAM_ARRAY_SIZE is:
ARRAY_SIZE ~= 4 x (last_level_cache_size x num_sockets) / size_of_double = last_level_cache_size
This reduces to a number of elements equal to the size of the last level cache of a single socket in bytes, assuming a node has two sockets. This is the minimum size unless other system attributes constrain it.
The array size only influences the capacity of STREAM to fully load the memory bus.
At capacity, the measured values should reach a steady state where increasing the value of STREAM_ARRAY_SIZE doesn’t influence the measurement for a certain number of processors.
For Crossroads, the benchmark was build with STREAM_ARRAY_SIZE=40000000 and NTIMES=20 with optmizations and OpenMP enabled.
make CC=`which mpicc` FF=`which mpifort` CFLAGS="-O2 -fopenmp -DSTREAM_ARRAY_SIZE=40000000 -DNTIMES=20" FFLAGS="-O2 -fopenmp -DSTREAM_ARRAY_SIZE=40000000 -DNTIMES=20"
2.4. Running
export OMP_NUM_THREADS=1
srun -n <num_processes> --cpu-bind=core ./stream-mpi.exe
Replace <num_processes> with the number of MPI processes you want to use. For example, if you want to use 4 MPI processes, the command will be:
export OMP_NUM_THREADS=1
srun -n 4 --cpu-bind=core ./stream-mpi.exe
2.5. Example Results
Results for STREAM are provided on the following systems:
Crossroads (see ATS-3/Crossroads)
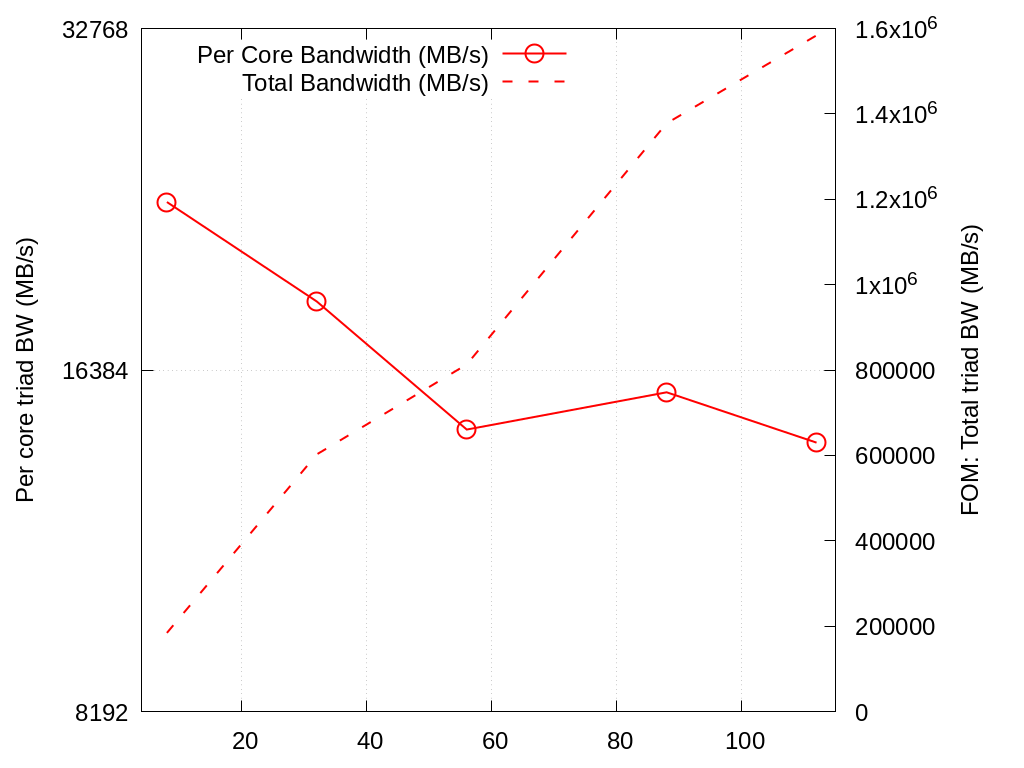
2.5.1. Crossroads
These results were obtained using the cce v15.0.1 compiler and cray-mpich v 8.1.25. Results using the intel-oneapi and intel-classic v2023.1.0 and the same cray-mpich were also collected; cce performed the best.
STREAM_ARRAY_SIZE=40000000 NTIMES=20
No. Cores |
Per Core Bandwidth (MB/s) |
Total Bandwidth (MB/s) |
|---|---|---|
8 |
2.304e+04 |
1.843e+05 |
32 |
1.883e+04 |
6.025e+05 |
56 |
1.452e+04 |
8.131e+05 |
88 |
1.566e+04 |
1.378e+06 |
112 |
1.414e+04 |
1.584e+06 |