3. Spatter
This is the documentation for the ATS-5 Benchmark Spatter - Scatter/Gather kernels.
3.1. Purpose
Micro-benchmark scatter/gather performance of current and future node-level architectures.
From the [Spatter] Benchmark Repository:
With this benchmark, we aim to characterize the performance of memory systems in a new way. We want to be able to make comparisons across architectures about how well data can be rearranged, and we want to be able to use benchmark results to predict the runtimes of sparse algorithms on these various architectures.
See [Spatter-Paper] for earlier details and results. Additionally, see [LANL-Memory-Wall] and [Spatter] for enhancements and additional features.
3.2. Characteristics
3.2.1. Problem
We have profiled the Flag and xRAGE applications to collect relevant gather/scatter patterns. These have been collected into a repository [LANL-Spatter], along with several utility scripts which allow us to perform weak scaling and strong scaling experiments with this data. The Flag patterns were obtained from a problem utilizing a 2D static mesh, while the xRAGE patterns were obtained from a 3D simulation of an asteroid impact.
3.2.2. Figure of Merit
The Figure of Merit is defined as the measured bandwidth in MB/s. This is measured for each rank to obtain the average bandwidth per rank. This is obtained by taking the total data movement divided by the runtime for the gather/scatter operation for each rank.
3.3. Building
Accessing the benchmark, memory access patterns, and scaling scripts [LANL-Spatter]
cd <path to benchmarks>
git submodule update --init --recursive
cd microbenchmarks/spatter
Set-up:
The setup script will
Download, untar, and prepare the Spatter input decks for the static_2d and asteroid problems.
Initialize your CPU configuration file (scripts/cpu_config.sh) with ATS-3 defaults and the GPU configurationo file (scripts/gpu_config.sh) with V100/A100 defaults
Will build Spatter for CPU and GPU. See the Spatter documentation and other build scripts (scripts/build_cpu.sh and scripts/build_cuda.sh) for further instructions for building with different compilers or for GPUs.
The scripts/setup.sh scripts has the following options
c: Toggle CPU Build (default: off)
g: Toggle GPU Build (default: off)
h: Print usage message
To setup and build for only the CPU, run the following:
bash scripts/setup.sh -c
Or to build only for the GPU, run:
bash scripts/setup.sh -g
To setup and build for both the CPU and GPU, run the following:
bash scripts/setup.sh -c -g
This setup script performs the following:
Untars the Pattern JSON files located in the datafiles directory
datafiles/flag/static_2d/001.fp.json
datafiles/flag/static_2d/001.nonfp.json
datafiles/flag/static_2d/001.json
datafiles/xrage/asteroid/spatter.json
Extracts patterns from datafiles/xrage/asteroid/spatter.json to separate JSON files located at datafiles/xrage/asteroid/spatter{1-9}.json
Generates default module files located in modules/cpu.mod and modules/gpu.mood
Contains generic module load statements for CPU and GPU dependencies
Assumes you are utilizing the module load system to configure environment. Change as needed (i.e. changes to PATH etc.) if you utilize a different system.
Populates the configuration file (scripts/cpu_config.sh) with reasonable defaults for a ATS-3 system
HOMEDIR is set to the directory this repository sits in
MODULEFILE is set to modules/cpu.mod
SPATTER is set to path of the Spatter CPU executable
ranklist is set to sweep from 1-112 ranks respectively for a ATS-3 type system
sizelist is set to reasonable defaults for strong scaling experiments (specifies the size of the pattern to truncate at)
count list is set to defaults of 1.
Populates the GPU configuration file (scripts/gpu_config.sh) with reasonable defaults for single-GPU throughput experiments on a V100 or A100 system
HOMEDIR is set to the directory this repository sits in
MODULEFILE is set to modules/gpu.mod
SPATTER is set to path of the Spatter GPU executable
ranklist is set to a constant of 1 for 8 different runs (8 single-GPU runs)
sizelist is set to reasonable defaults for strong scaling experiments (specifies the size of the pattern to truncate at)
countlist is set to reasonable defaults to control the number of gathers/scatters performed by an experiment. This is the parameter that is varied to perform throughput experiments.
Attempts to build Spatter on CPU with CMake, GCC, and MPI and on GPU with CMake and NVCC
You will need CMake, GCC, and MPI loaded into your environment (include them in your modules/cpu.mod if not already included)
You will need CMake, CUDA, and NVCC loaded into your environment for the GPU build (include them in your modules/gpu.mod)
3.3.1. Optional Manual Build
In the case you need to build manually, the following scripts can be modified to build for CPU:
bash scripts/build_cpu.sh
and to build for GPUs which support CUDA:
bash scripts/build_cuda.sh
Further build documentation can be found here: [Spatter]
3.4. Running
Running a Scaling Experiment
This will perform a weak scaling experiment
The scripts/scaling.sh script has the following options (a scripts/mpirunscaling.sh script with identical options has been provided if required to use mpirun rather than srun):
a: Application name
p: Problem name
f: Pattern name
n: User-defined run name (for saving results)
c: Core binding (optional, default: off)
g: Toggle GPU (optional, default: off)
m: Toggle Atomics (optional, default: off)
r: Toggle count parameter on pattern with countlist (default: off)
s: Toggle pattern size limit (optional, default: off for weak scaling, will be overridden to on for strong scaling)
t: Toggle throughput plot generation (optional, default: off)
w: Toggle weak/strong scaling (optional, default: off = strong scaling)
x: Toggle plotting/post-processing (optional, default: on)
h: Print usage message
The Application name, Problem name, and Pattern name each correspond to subdirectories in this repository containing patterns stored as Spatter JSON input files.
All Figures use solid lines for Gathers and dashed lines for Scatters.
3.4.1. Crossroads
These weak-scaling experiements were ran on 1, 2, 4, 8, 16, 32, 56, 64, 96, and 112 ranks with a single Crossroads node.
These experiments were ran with core-binding turned on and plotting enabled.
3.4.1.1. xRAGE Asteroid Spatter Pattern 5
Weak-scaling experiment for the pattern in datafiles/xrage/asteroid/spatter5.json. Results will be found in spatter.weakscaling/Crossroads/xrage/asteroid/spatter5/ and Figures will be found in figures/spatter.weakscaling/Crossroads/xrage/asteroid/spatter5
This pattern is a Gather with a length of 8,368,968 elements with a target vector length of 1,120,524.
bash scripts/scaling.sh -a xrage -p asteroid -f spatter5 -n Crossroads -c -w
No. Cores |
Average Bandwidth per Rank (MB/s) |
|---|---|
1 |
7404.13 |
2 |
7401.11 |
4 |
7035.59 |
8 |
6612.21 |
16 |
5495.96 |
32 |
4705.42 |
56 |
4596.22 |
64 |
4534.47 |
96 |
4258.25 |
112 |
4220.44 |
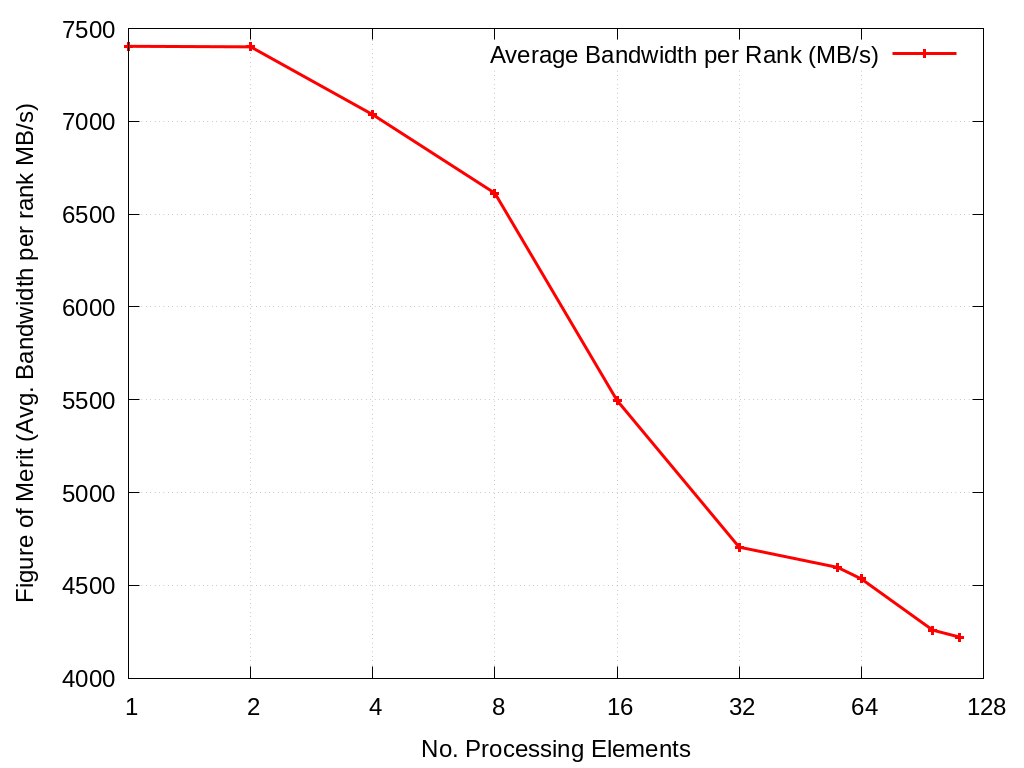
Fig. 3.12 Spatter Weak Scaling Performance for xRAGE Spatter Pattern 5 on Crossroads
3.4.1.2. xRAGE Asteroid Spatter Pattern 9
Weak-scaling experiment for the pattern in datafiles/xrage/asteroid/spatter5.json. Results will be found in spatter.weakscaling/Crossroads/xrage/asteroid/spatter9/ and Figures will be found in figures/spatter.weakscaling/Crossroads/xrage/asteroid/spatter9
This pattern is a Scatter with a length of 6,664,304 elements with a target vector length of 2,051,100.
bash scripts/scaling.sh -a xrage -p asteroid -f spatter9 -n Crossroads -c -w
No. Cores |
Average Bandwidth per Rank (MB/s) |
|---|---|
1 |
6119.98 |
2 |
6107.82 |
4 |
5843.52 |
8 |
5669.69 |
16 |
5390.57 |
32 |
4308.68 |
56 |
4245.79 |
64 |
3830.14 |
96 |
3708.73 |
112 |
3576.65 |
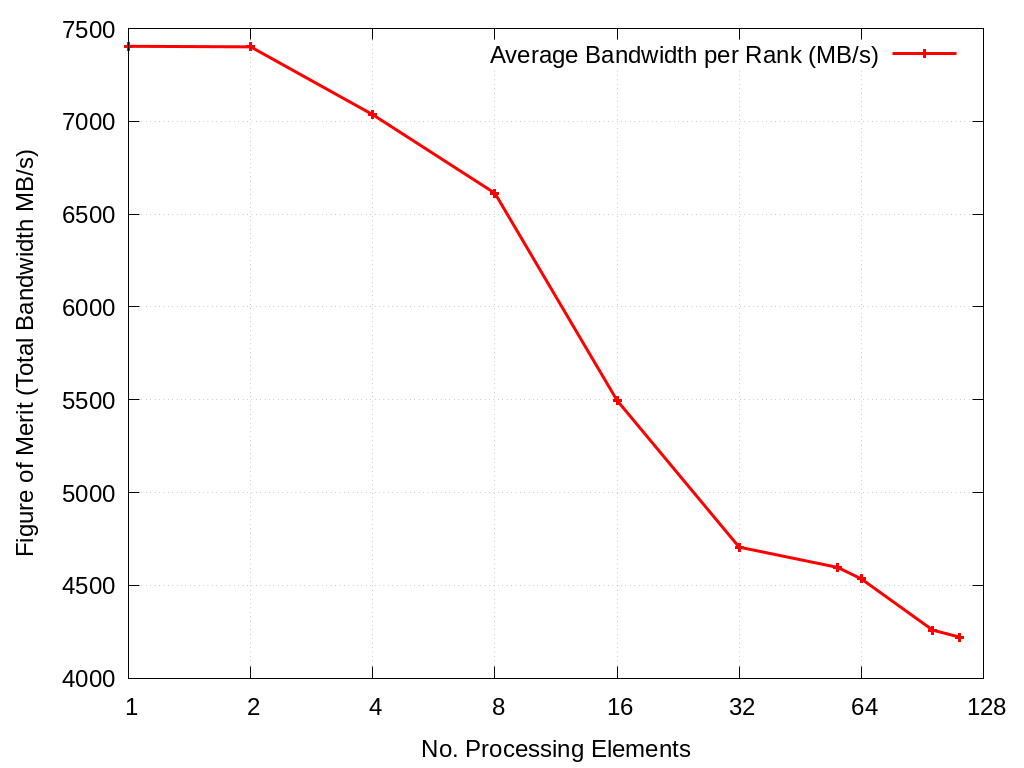
Fig. 3.13 Spatter Weak Scaling Performance for xRAGE Spatter Pattern 9 on Crossroads
3.4.2. H100
Strong-Scaling throughput experiments with plotting enabled.
3.4.2.1. xRAGE Asteroid Spatter Pattern 5
Throughput experiment for the pattern in datafiles/xrage/asteroid/spatter5.json. Results will be found in spatter.strongscaling/H100/xrage/asteroid/spatter5/ and Figures will be found in figures/spatter.strongscaling/H100/xrage/asteroid/spatter5/
bash scripts/scaling.sh -a xrage -p asteroid -f spatter5 -n H100 -g -s -r -t
Data Transferred (MB) |
Total Bandwidth (MB/s) |
|---|---|
4.194304 |
728177.77 |
8.388608 |
1083239.69 |
16.777216 |
1476867.62 |
33.554432 |
1730323.39 |
66.951744 |
1629471.97 |
133.903488 |
1743534.92 |
267.806976 |
1821320.63 |
535.613952 |
1861425.36 |
1071.227904 |
1882041.47 |
2142.455808 |
1893056.87 |
4284.911616 |
1898720.78 |
8569.823232 |
1901308.97 |
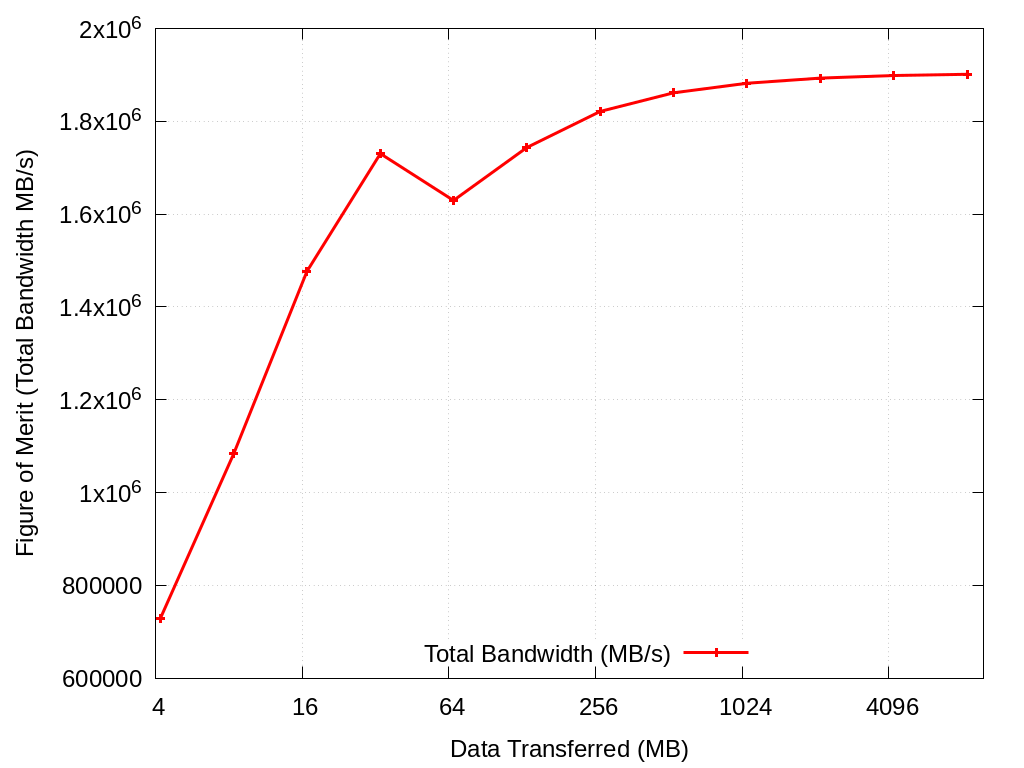
Fig. 3.14 Spatter Throughput on H100 xRAGE Asteroid Pattern 5 on H100
3.4.2.2. xRAGE Asteroid Spatter Pattern 9
Throughput experiment for the pattern in datafiles/xrage/asteroid/spatter9.json. Results will be found in spatter.strongscaling/H100/xrage/asteroid/spatter9/ and Figures will be found in figures/spatter.strongscaling/H100/xrage/asteroid/spatter9/
Note that we need to enable atomics with the -m flag since this is a scatter pattern which overwrites the same location multiple times. Results with and without atomics are included, but the results with atomics enabled is the benchmarked performance number of importance.
bash scripts/scaling.sh -a xrage -p asteroid -f spatter9 -n H100 -g -s -r -t -m
Data Transferred (MB) |
Total Bandwidth without Atomics (MB/s) |
Total Bandwidth with Atomics (MB/s) |
|---|---|---|
4.194304 |
615361.48 |
492751.9 |
8.388608 |
916587.43 |
677374.66 |
16.777216 |
1044398.45 |
786038.96 |
33.554432 |
1025000.99 |
741567.16 |
53.314432 |
1098994.71 |
792614.68 |
106.628864 |
1167128.51 |
831375.29 |
213.257728 |
1200991.87 |
853850.6 |
426.515456 |
1229803.27 |
866450.52 |
853.030912 |
1239870.47 |
872005.75 |
1706.061824 |
1243804.45 |
875384.74 |
3412.123648 |
1246581.74 |
876456.83 |
6824.247296 |
1248311.13 |
876824.44 |
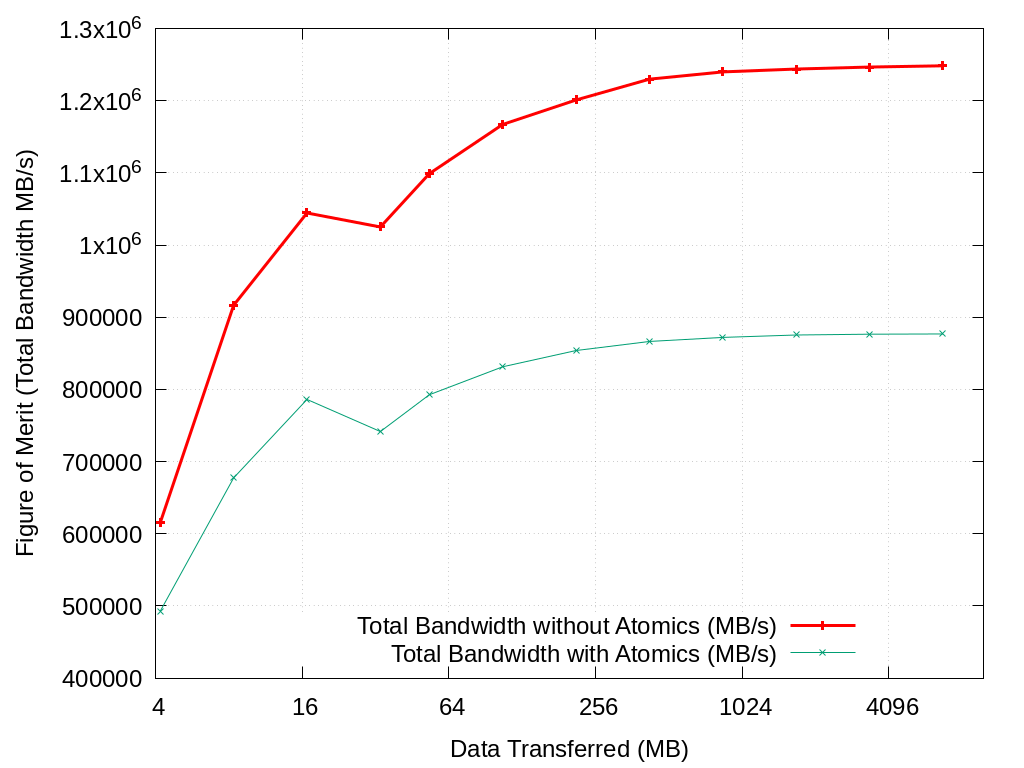
Fig. 3.15 Spatter Throughput on H100 xRAGE Asteroid Pattern 9 on H100
3.5. References
Patrick Lavin, Jeffrey Young, Jered Dominguez-Trujillo, Agustin Vaca Valverde, Vincent Huang, James Wood, ‘Spatter’, 2023. [Online]. Available: https://github.com/hpcgarage/spatter
Lavin, P., Young, J., Vuduc, R., Riedy, J., Vose, A. and Ernst, D., Evaluating Gather and Scatter Performance on CPUs and GPUs. In The International Symposium on Memory Systems (pp. 209-222). September 2020.
Jered Dominguez-Trujillo, Kevin Sheridan, Galen Shipman, ‘Spatter’, 2023. [Online]. Available: https://github.com/lanl/spatter. [Accessed: 19- Apr- 2023]
Shipman, J. Dominguez-Trujillo, K. Sheridan and S. Swaminarayan, “Assessing the Memory Wall in Complex Codes,” 2022 IEEE/ACM Workshop on Memory Centric High Performance Computing (MCHPC), Dallas, TX, USA, 2022, pp. 30-35, doi: 10.1109/MCHPC56545.2022.00009.